2. Data en methoden
2.1 Inleiding
In dit hoofdstuk bespreken we de data en methoden op basis waarvan een model is ontwikkeld om het risico op voortijdig schoolverlaten (vsv) in het vo en het mbo zo goed mogelijk te schatten. Dit hoofdstuk is als volgt opgezet: in paragraaf 2.2 bespreken we de gebruikte databronnen. In paragraaf 2.3 gaan we in op de populatie waarvoor de kans op vsv is geschat. Vervolgens komt in paragraaf 2.4 de operationalisering van vsv aan bod. In paragraaf 2.5 worden de kenmerken besproken die zijn meegenomen in het onderzoek. De imputatie van het opleidingsniveau van de ouders komt aan bod in paragraaf 2.6. In paragraaf 2.7 gaan we tenslotte in op de gebruikte analysemethode. Deze methode bestaat uit een aantal stappen die één voor één zullen worden uitgelegd.
2.2 Gebruikte databronnen
In dit onderzoek is gebruik gemaakt van gegevens uit het Stelsel van Sociaal-Statistische Bestanden (SSB) van het CBS. Het SSB bevat een groot aantal microdatabestanden met informatie uit administratieve overheidsregisters over personen en huishoudens. Het CBS ontvangt deze informatie vanwege zijn wettelijke taak. De data bevatten geen namen, geen adressen en geen burgerservicenummers. Om gegevens uit verschillende bronnen aan elkaar te verbinden worden gepseudonimiseerde koppelsleutels gebruikt die buiten het SSB geen betekenis hebben. Individuele personen zijn hierdoor niet direct te identificeren. Zie bijlage 2 voor meer informatie over de bestanden uit het SSB die zijn gebruikt.
2.3 Populatie
De groep leerlingen en studenten voor wie de kans op vsv geschat zal worden noemen we de populatie. De populatie in dit onderzoek bestaat uit jongeren die op 1 oktober 2018 staan ingeschreven in het vo, mbo of voortgezet algemeen volwassenenonderwijs (vavo) (cohort 2018/’19). Er is gekozen voor dit cohort omdat dit het meeste recente cohort voor de start van de coronacrisis is. Tijdens de coronacrisis waren er afwijkende patronen in de ontwikkeling van vsv te zien. Het is niet wenselijk om dit mee te nemen bij de ontwikkeling van het model, omdat dit mogelijk tot een vertekend beeld kan leiden.
Daarnaast bevat de populatie enkel jongeren die op 1 oktober 2018 (het startmoment, t0) 11 tot en met 26 jaar oud waren1). De geplande verhoging van de vsv-leeftijd is meegenomen in de ontwikkeling van de modellen. Daarnaast wordt, zoals al benoemd werd in de inleiding, onderscheid gemaakt tussen een vo- en mbo-populatie. Vavo-leerlingen zijn een relatief kleine groep waardoor voor hen geen apart model kan worden samengesteld. Deze leerlingen worden daarom tot de vo-populatie gerekend.
Om te onderzoeken welke jongeren een grotere kans hebben om vsv’er te worden moet de populatie alleen bestaan uit personen die op het startmoment (t0) nog kans hebben om vsv’er te worden. Dit betekent dat we de gebruikelijke startpopulatie om het aandeel nieuwe vsv’ers te meten nader moeten afbakenen tot jongeren die op 1 oktober 2018 nog géén startkwalificatie hadden. Jongeren die op 1 oktober 2018 al wel een startkwalificatie hadden kunnen namelijk per definitie geen vsv’er meer worden op 1 oktober 2019 (t1). Een startkwalificatie is een diploma op ten minste havo-, vwo- of mbo 2-niveau. Dit wordt door het CBS gemeten via het zogenaamde opleidingsniveaubestand (zie bijlage 2).
In het onderzoek is bovenstaande populatie ook vergeleken met een eerder cohort (2017/’18) om het model te valideren, dat wil zeggen dat we onderzoeken of de resultaten in het ontwikkelde model robuust zijn. Dit cohort noemen we in het rapport het validatiecohort.
In dit onderzoek volgen we de methode van het CBS om vsv in kaart te brengen. In een aanvullende analyse om het model te valideren, is de modelselectie ook toegepast op een dataset van de Dienst Uitvoering Onderwijs (DUO) en onderzocht of dit leidt tot een vergelijkbare selectie en volgorde van kenmerken. Zowel het CBS als DUO sluiten personen uit die op t0 (1 oktober 2018) staan ingeschreven in het praktijkonderwijs, de Engelse Stroom, het Internationaal Baccalaureaat, de volwasseneneducatie of het speciaal onderwijs. Daarnaast sluiten ze beide personen uit die op t1 (1 oktober 2019) een vrijstelling van de leerplicht hebben. Er zijn echter ook een aantal verschillen tussen de methodes van het CBS en DUO.
Een belangrijk verschil tussen beide methodes is dat het CBS de Basisregistratie Personen (BRP) gebruikt om af te bakenen welke jongeren op t0 en t1 in Nederland wonen. DUO gebruikt hiervoor de Registratie Onderwijsdeelnemers (ROD, voorheen bekend als BRON). In de data van DUO komen in het vo hierdoor enkele honderden leerlingen voor die niet in de BRP staan ingeschreven. Voor deze leerlingen kan geen informatie uit andere registers in het SSB worden aangekoppeld. Hierdoor hebben wij de betreffende leerlingen uiteindelijk niet in de vergelijkende analyse meegenomen. Een ander verschil is dat er in de dataset van DUO nog sprake is van een leeftijdgrens van 22 jaar op t0. Hierbij kan dus geen rekening gehouden worden met de verhoging van de vsv-leeftijd. Ook zijn eerstejaars nieuwkomers niet meegenomen in de populatie van DUO. Tevens worden jongeren die op t1 zijn uitgestroomd naar bepaalde onderwijssoorten, zoals speciaal onderwijs of praktijkonderwijs niet meegenomen in de CBS-populatie maar wel in de DUO-populatie. Tot slot neemt DUO bij het bepalen van een startkwalificatie ook diploma’s mee van niet-bekostigde instellingen. Het CBS neemt dit enkel indirect en slechts gedeeltelijk mee via het opleidingsniveaubestand (zie bijlage 2).
2.4 Operationalisering vsv
Vsv’ers zijn jongeren die op 1 oktober 2019 (t1) het bekostigd onderwijs hebben verlaten vanuit het vo, mbo of vavo zonder een startkwalificatie. Het zijn dus jongeren tot 27 jaar die op 1 oktober 2018 (t0) ingeschreven staan in het bekostigd vo, mbo of vavo en op 1 oktober 2019 (t1) niet meer ingeschreven staan in het bekostigd onderwijs en (nog steeds) geen startkwalificatie hebben.
De precieze definitie van vsv verschilt tussen het CBS en DUO. DUO rekent de volgende jongeren niet tot vsv’ers:
- jongeren die doorstromen naar niet-bekostigd onderwijs;
- jongeren die een opleiding gaan volgen bij politie of defensie;
- jongeren die tussen 1 oktober en 31 december in jaar t1 alsnog een startkwalificatie behalen;
- jongeren met een mbo-entreediploma die 12 uur of meer werken op 1 oktober.
Zoals ook te zien is in tabel 2.4.1 is het percentage vsv daarom lager in de DUO-populatie in vergelijking met de CBS-populatie. Daarnaast wordt, zoals in de vorige paragraaf al beschreven werd, in de DUO-data geen rekening gehouden worden met de verhoging van de vsv-leeftijd. In deze data wordt nog de oude grens gebruikt van 23 jaar. Uit onderstaande tabel komt ook duidelijk naar voren dat vsv minder vaak voorkomt onder scholieren op het vo dan onder mbo-studenten.
| vo | mbo | |||
|---|---|---|---|---|
| aantal | % | aantal | % | |
| CBS-data | ||||
| Wel vsv'er | 7 430 | 0,8 | 27 820 | 7,9 |
| Geen vsv'er | 921 400 | 99,2 | 326 460 | 92,1 |
| Totaal | 928 830 | 100 | 354 280 | 100 |
| DUO-data | ||||
| Wel vsv'er | 4 960 | 0,5 | 21 720 | 6,4 |
| Geen vsv'er | 923 520 | 99,5 | 515 020 | 93,6 |
| Totaal | 928 480 | 100 | 336 740 | 100 |
2.5 Onderzochte kenmerken
Samen met de begeleidingscommissie hebben het CBS en het ministerie van OCW eerst een lijst met mogelijke verklarende variabelen van vsv opgesteld. Deze lijst is uitgebreid met kenmerken die in twee eerdere onderzoeken van het CBS naar vsv van belang bleken te zijn. Ook zijn op basis van de uitkomsten van ander CBS-onderzoek naar verdeelmodellen nog aanvullende kenmerken toegevoegd.
Een aantal van de kenmerken in deze lijst is op basis van de registraties die het CBS (op dit moment) tot zijn beschikking heeft niet in kaart te brengen. Dit kan zijn omdat gegevens (nog) niet beschikbaar zijn bij het CBS of omdat sommige gegevens niet integraal worden gemeten en daardoor niet voor alle leerlingen of studenten beschikbaar zijn. Daarnaast was een aantal zeer vergelijkbare suggesties opgenomen (zie volgende alinea’s bij de bespreking van de kenmerken). In overleg met inhoudelijke experts bij het CBS is voor het best passende kenmerk gekozen.
In deze paragraaf worden de kenmerken beschreven die in het onderzoek zijn meegenomen als mogelijke verklarende variabelen van vsv. Eerst zullen de kenmerken worden benoemd die voor zowel het vo als het mbo in kaart gebracht kunnen worden. Vervolgens zullen nog enkele onderwijsgerelateerde kenmerken worden benoemd die specifiek op één van beide onderwijssoorten (vo of mbo) van toepassing zijn. In sommige gevallen zijn dezelfde kenmerken onderzocht voor zowel het vo als het mbo, maar wel met verschillende operationaliseringen. Een uitgebreid overzicht van de operationalisering van de kenmerken is te vinden in bijlage 3.
Sociaal-demografische kenmerken
Twee eerdere onderzoeken van het CBS in 2020 en 2021 naar de relatie tussen multiproblematiek en vsv lieten zien dat geslacht, leeftijd en migratieachtergrond gerelateerd zijn aan de kans op vsv. Daarnaast bleken jongeren die niet meer bij beide juridische ouders wonen een hogere kans te hebben op vsv. Dit gold ook voor jongeren van wie hun juridische ouder niet bekend is in de registers van het CBS, bijvoorbeeld omdat de ouder in het buitenland woont. Ook waren de hoogte van het huishoudinkomen en het hoogst behaalde opleidingsniveau van de vader en moeder van belang. Het opleidingsniveau is niet voor alle personen bekend. Daarom zijn ontbrekende waarden geïmputeerd (zie paragraaf 2.6 voor meer informatie).
Deze sociaal-demografische kenmerken zijn ook meegenomen in eerder CBS-onderzoek naar de ontwikkeling van verdeelmodellen voor onderwijsachterstanden. In het uiteindelijke model voor de Onderwijs Achterstanden Indicator in het primair onderwijs zijn de volgende kenmerken opgenomen: opleidingsniveau van moeder en vader, herkomstland van de jongere en verblijfsduur van de moeder in Nederland.
De begeleidingscommissie onderstreepte het belang van het toevoegen van deze sociaal-demografische kenmerken, met name de leeftijd en de migratieachtergrond en het aantal verblijfsjaren in Nederland van de jongere. Ook de aanwezigheid van een laag huishoudinkomen, armoede en bijstand en de sociaaleconomische status werden aangedragen. Het CBS heeft dit op advies van een inhoudelijke expert samengevoegd tot één kenmerk, te weten ‘welvaart’. Hierbij wordt rekening gehouden met de hoogte van het huishoudinkomen én van het vermogen. Tot slot adviseerde de commissie om het hebben van een bijbaan op te nemen in de lijst van mogelijke verklarende variabelen van vsv. Dit is geoperationaliseerd door middel van het aantal uren dat een jongere per week werkt.
De volgende sociaal-demografische kenmerken zijn uiteindelijk opgenomen in de lijst:
- Geslacht van de jongere
- Leeftijd van de jongere
- Herkomstland (van jongere en ouders)
- Migratieachtergrond (van jongere en ouders)
- Verblijfsduur in Nederland (van jongere en ouders)
- Ouderlijke structuur
- Ouders niet bekend
- Hoogst behaalde opleiding van de ouders
- Welvaart van het huishouden
- Huishoudinkomen onder de lage inkomensgrens
- Aantal gewerkte uren door de jongere
Aanwezigheid van problemen
Problemen van jongeren en hun ouders hangen sterk samen met de kans dat een jongere een vsv’er wordt. Het CBS heeft in 2020 een literatuurstudie uitgevoerd naar de aanwezigheid van (multi)problematiek bij de jongere en de relatie met vsv. Vervolgens heeft het CBS in 2021 onderzocht welke van deze problemen het sterkst samenhangen met vsv. Deze studie liet zien dat psychosociale problemen van de jongere en van de moeder sterk samenhangen met de kans op vsv. Hierbij is gekeken naar het gebruik van jeugdhulp en/of GGZ. Daarnaast bleken gezondheidsproblemen de kans op vsv te vergroten. In dit huidige onderzoek maken we, op advies van de inhoudelijke experts van het CBS, onderscheid tussen langdurige en acute gezondheidsproblemen. Verder was te zien dat jongeren die verdacht zijn geweest van een delict een verhoogde kans hebben op vsv. Registratie door de politie als verdachte van een misdrijf is daarom toegevoegd aan de lijst. Ook schulden in het huishouden leiden tot een hogere kans op vsv. Dit kan op verschillende manieren gemeten worden. In onze studie is, in overleg met een inhoudelijk expert, gekozen om zowel een specifieke variabele (wanbetaler van de zorgverzekering) als een complexere variabele (geregistreerde problematische schulden, waarbij is gekeken naar een breder scala aan mogelijke schulden) op te nemen in de lijst. Tot slot droeg de begeleidingscommissie de suggestie aan om te kijken naar ongeoorloofd verzuim van de jongere. Er zijn op dit moment enkel registraties beschikbaar rondom de overtreding van de leerplichtwet bij Bureau Halt.
Samenvattend zijn de volgende probleemgerelateerde kenmerken uiteindelijk toegevoegd aan de lijst:
- Psychosociale problemen (bij jongere en moeder)
- Langdurige gezondheidsproblemen bij de jongere
- Acute gezondheidsproblemen bij de jongere
- Jongere is verdachte van een delict
- Ouders staan geregistreerd als wanbetaler van de premie van de zorgverzekering
- Geregistreerde problematische schulden
- Ongeoorloofd verzuim door de jongere
Omgevingskenmerken
De omgeving waarin de jongere woont kan ook invloed hebben op de kans dat een jongere vsv’er wordt. Op advies van de begeleidingscommissie zijn daarom de volgende kenmerken toegevoegd aan de lijst. Zo kan een hoge jeugdwerkloosheid of veel armoede in de buurt een jongere aanmoedigen om wel een diploma te behalen en zo zijn of haar kansen op de arbeidsmarkt te vergroten. Aan de andere kant kan het ook zo zijn dat de jongere hierdoor ontmoedigd wordt en daarom besluit te stoppen met de opleiding. Een sterk stedelijke omgeving kan extra kansen bieden voor een jongere, maar ook mogelijk voor afleiding zorgen. In welke richting deze effecten lopen zal bij de ontwikkeling van het model naar voren komen.
Kortom, de volgende omgevingskenmerken zijn opgenomen in de lijst met te onderzoeken variabelen:
- Stedelijkheid van de buurt
- Jeugdwerkloosheid in de gemeente
- Lage welvaart in de buurt
Onderwijs gerelateerde kenmerken
Een aantal kenmerken kan alleen onderzocht worden voor één van de onderzoekspopulaties. Voor het vo zijn twee specifieke kenmerken voorgesteld. Ten eerste laat het CBS-onderzoek uit 2020 duidelijke verschillen zien in het aandeel vsv’ers naar onderwijssoort. Dit aandeel lag het hoogst bij leerlingen uit leerjaar 3-4 van het vmbo. De begeleidingscommissie gaf hierbij aan dat het ook waardevol is om specifiek de leerwegen binnen het vmbo te onderscheiden. Ook is het van belang om onderscheid te maken tussen jongeren die het reguliere voortgezet onderwijs volgen en degenen die vavo volgen. De laatste categorie kent een hoger aandeel vsv’ers. Ten tweede is voor het vo op basis van het leerjaar2) en de leeftijd gekeken of jongeren vertraging hebben opgelopen in hun onderwijsloopbaan.
Voor het mbo zijn vier extra variabelen meegenomen. Ten eerste bleek uit eerder onderzoek dat er grote verschillen waren in het aandeel vsv’ers tussen niveaus binnen het mbo. Het aandeel was veruit het hoogst bij de entreeopleiding. Ten tweede waren er ook verschillen te zien in de leerweg: zo lag het aandeel vsv’ers veel hoger bij studenten die de beroepsbegeleidende leerweg (BBL) volgden in vergelijking met studenten die de beroepsopleidende leerweg (BOL) volgden. De begeleidingscommissie stelde daarnaast voor om naar de studierichting van de gevolgde opleiding te kijken en het niveau van de vooropleiding van de student.
Samengevat zijn de volgende onderwijs gerelateerde variabelen opgenomen:
Voor het vo:
- Combinatie onderwijssoort en leerjaar
- Vertraging
Voor het mbo:
- Niveau
- Leerweg
- Studierichting (ISCED-indeling)
- Hoogst behaalde opleiding van de student
2.6 Imputatie opleidingsniveau van de ouders
De meeste kenmerken die in dit onderzoek worden gebruikt zijn bekend voor (bijna) alle jongeren in de populatie. Echter, de kenmerken opleidingsniveau van de moeder en de vader ontbreken voor een substantieel deel van de populatie. De opleidingsgegevens zijn afkomstig uit centrale opleidingsregistraties die in Nederland tussen de jaren 1980 en 2010 beschikbaar zijn gekomen, aangevuld met enquêtegegevens op steekproefbasis. Ontbrekende waarden komen daarom met name voor bij oudere mensen en mensen die hun opleiding in het buitenland hebben gevolgd. Eerder is bij de ontwikkeling van een indicator voor onderwijsachterstanden in het primair onderwijs door het CBS in 2016 een imputatiemethode ontwikkeld voor het opleidingsniveau van de ouders. Bij deze imputatiemethode worden de ontbrekende opleidingsniveaus vervangen door geschatte waarden, afkomstig uit een verdeling van mogelijke opleidingsniveaus. Bij het bepalen van de te imputeren waarden wordt rekening gehouden met een aantal hulpkenmerken die wel altijd bekend zijn. Dezelfde imputatiemethode is in 2021 ook toegepast op leerlingen in het vo.
Voor details over de gebruikte imputatiemethode, inclusief een test van de methode in een simulatiestudie, verwijzen we naar dit rapport. De methode is in het huidige onderzoek op dezelfde manier toegepast als eerder, met alleen enkele verschillen in de keuze van hulpkenmerken die worden meegenomen bij het imputeren:
- In het oorspronkelijke onderzoek werd de Cito-eindtoetsscore van een leerling gebruikt als hulpkenmerk bij het imputeren, omdat dit de doelvariabele was van de analyse uit dat onderzoek. Hier is in plaats daarvan het vsv-kenmerk gebruikt.
- Voor het hulpkenmerk herkomstland van vader en moeder is hier gebruikgemaakt van de nieuwe standaardindeling van het CBS.
- Voor het hulpkenmerk leeftijd van vader en moeder is een andere indeling in categorieën gebruikt. Er is vijf jaar opgeteld bij de grenzen tussen de categorieën om beter aan te sluiten bij de leeftijdsverdeling in onze doelpopulaties: ouders van jongeren in het vo en mbo zijn gemiddeld ouder dan ouders van leerlingen in het primair onderwijs.
De geïmputeerde opleidingsniveaus zijn willekeurige trekkingen uit een verdeling van mogelijke waarden. Om bij het schatten van modellen rekening te houden met de extra onzekerheid in de geïmputeerde waarden kan gebruik worden gemaakt van multipele imputatie (Rubin, 1987). Hierbij worden alle ontbrekende waarden meerdere keren geïmputeerd en wordt elk model meerdere keren geschat. Multipele imputatie maakt het uitvoeren van de stepwise aanpak die hieronder in paragraaf 2.7 wordt beschreven wel complexer.
Aangezien in dit onderzoek imputatie alleen speelt bij het opleidingsniveau van de ouders, en niet op voorhand duidelijk is of een van deze kenmerken als relevant naar voren zal komen, hebben we ervoor gekozen om in eerste instantie de hele aanpak te doorlopen voor één imputatieronde. Verder herhalen we de analyse voor één andere imputatieronde, ter controle dat de conclusies hierdoor niet veranderen. Als uit deze controle zou blijken dat de eerste imputatieronde stabiel is én het opleidingsniveau van de vader en/of moeder belangrijk is in het modelleren van vsv, houden we het bij de eerste imputatieronde. Als deze niet stabiel blijkt, zal multipele imputatie toegepast worden.
2.7 Opzet analyse
Aanpak
Het doel van dit onderzoek is om, voor zowel het vo als het mbo, een logistisch regressiemodel te ontwikkelen waarmee op individueel niveau de kans op vsv kan worden geschat. Gezien het grote aantal achtergrondkenmerken dat onderzocht moet worden en gezien de grootte van de beschikbare dataset, is ervoor gekozen om de analyses voor vo en mbo op te delen in verschillende stappen, zoals weergegeven in figuur 2.7.1. In dit hoofdstuk zullen deze stappen in detail besproken worden en zal de gebruikte analysemethode, logistische regressie, kort worden toegelicht.
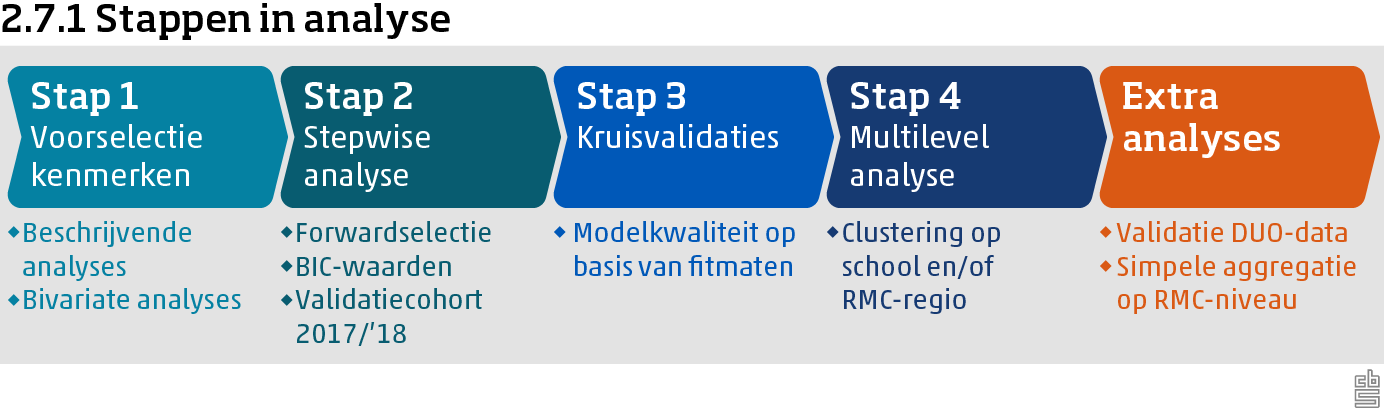
Gedurende deze stappen zullen de volgende onderzoeksvragen beantwoord worden:
- Welke combinatie van kenmerken uit paragraaf 2.5 kan het beste worden gebruikt om met een logistisch regressiemodel de kans op vsv te schatten (stap 1 en 2)?
- Hoe goed is dit model met de beste combinatie van kenmerken in staat om de kans op vsv voor individuele leerlingen en studenten te schatten (stap 3)?
- In hoeverre is het nuttig om in dit model rekening te houden met clustering per school of RMC-regio via een multilevel-component (stap 4)?
- In hoeverre kan het model gevalideerd worden met behulp van het DUO-cohort (extra analyse)?
- Hoe ziet een eerste beeld van een simpele aggregatie van de geschatte kansen op vsv op RMC-regio niveau eruit (extra analyse)?
Voor de ontwikkeling van de modellen gebruiken we data van leerlingen en studenten uit het cohort 2018/’19. Daarnaast worden data van leerlingen en studenten uit het cohort 2017/’18 gebruikt om bepaalde keuzes in de modelselectie te valideren. Voor alle analyses in dit rapport geldt dat zij worden uitgevoerd op de data van het cohort 2018/’19, tenzij anders aangegeven.
Logistische regressieanalyse
Met een regressieanalyse kan de samenhang tussen een afhankelijke variabele (vsv) en onafhankelijke variabelen (de opgestelde lijst met achtergrondkenmerken) onderzocht worden. Of een jongere wel of geen vsv’er wordt is een zogenaamde ‘dichotome’ uitkomst (de uitkomst kan óf de waarde 0 óf de waarde 1 aannemen). Om dichotome uitkomsten te schatten wordt vaak gebruik gemaakt van logistische regressieanalyse. Met deze techniek kan de samenhang tussen achtergrondkenmerken en een dichotome uitkomst berekend worden door te werken met een kansverhouding (de ‘odds’). In de huidige analyse is de odds gelijk aan de kans dat een persoon wel vsv’er wordt op t1 gedeeld door de kans dat de persoon geen vsv’er wordt op t1. Een odds van één geeft aan dat de kans om vsv’er te worden even groot is als de kans om dit niet te worden (dat wil zeggen: beide kansen zijn gelijk aan 0,5). Een odds boven de één geeft aan dat de kans om vsv’er te worden groter is, terwijl een odds tussen nul en één het omgekeerde betekent.
Vervolgens kan binnen de analyse gekeken worden welke achtergrondkenmerken samenhangen met de odds op vsv. Dat kan gedaan worden met behulp van de ‘odds ratio’ (OR). Alle achtergrondkenmerken in onze analyse zijn categoriale variabelen, wat betekent dat ze ingedeeld zijn in categorieën (zie bijlage 3 voor de operationalisering van alle kenmerken). Het kenmerk geslacht bestaat bijvoorbeeld uit de categorieën man en vrouw. Voor elk achtergrondkenmerk wordt één categorie de referentiecategorie (bijvoorbeeld man). Vervolgens wordt van elke andere categorie gekeken wat de odds op vsv is ten opzichte van de odds van deze referentiegroep. Dit is de odds ratio. Een odds ratio van 1,5 wil in dit geval dan zeggen dat de odds op vsv voor vrouwen 1,5 keer zo hoog is als voor mannen, gegeven dat alle andere kenmerken in het model hetzelfde zijn. Voor een uitgebreidere beschrijving van logistische regressie, zie bijlage 4.1. In de volgende paragrafen bespreken we de stappen zoals weergegeven in figuur 2.7.1.
Stap 1: Voorselectie kenmerken
Om te onderzoeken welke combinatie van achtergrondkenmerken de kans op vsv zo goed mogelijk kan schatten, is als eerste de samenhang tussen de kans op vsv en elk van de voorgestelde kenmerken afzonderlijk bekeken. Hiertoe berekenen we voor elk achtergrondkenmerk een kruistabel met het aantal jongeren dat wel of niet vsv’er is geworden op t1. Daarnaast zijn er eenvoudige (bivariate) logistische regressies uitgevoerd om met behulp van odds ratio’s vast te stellen of er een mogelijke samenhang is tussen het kenmerk en vsv. Bovendien wordt de mate van samenhang tussen het achtergrondkenmerk en vsv geëvalueerd met Cramérs V.3) Cramérs V ligt altijd tussen 0 en 1, waarbij 0 wijst op afwezigheid van samenhang en 1 op perfecte samenhang tussen het achtergrondkenmerk en vsv.
De resultaten van stap 1 worden gebruikt om een definitieve selectie te maken van achtergrondkenmerken die meegenomen worden in het verdere traject en om de categorieën van deze kenmerken definitief af te bakenen. Kenmerken die niet of nauwelijks samen lijken te hangen met vsv, of waarbij de gevonden odds ratio’s vanuit inhoudelijk oogpunt niet kunnen worden verklaard, zullen in deze stap afvallen.
Bij het kiezen van een model om de kans op vsv te schatten streven we enerzijds naar een model dat zo goed mogelijk past bij de beschikbare data. Anderzijds is de wens vanuit het ministerie van OCW om het model eenvoudig en transparant te houden. Naarmate de complexiteit van het model groter wordt, neemt namelijk ook het risico op overfitting toe: het geschatte model past dan met name goed bij de populatie van jongeren waarop het model is geschat, maar mogelijk minder goed bij andere populaties van jongeren, bijvoorbeeld van een jaar eerder of later. Het model zou dan minder geschikt zijn voor gebruik in een verdeelmodel over een langere periode. Om te evalueren hoe goed een model past bij de data, rekening houdend met de complexiteit van het model, kijken we in de volgende stappen naar een aantal verschillende fitmaten (zie bijlage 4.1.2) en valideren we de resultaten op basis van het validatiecohort en het DUO-cohort.
Stap 2: Stepwise analyse
Met de overgebleven kenmerken wordt een stepwise analyse uitgevoerd voor een verdere selectie van kenmerken. Hierbij wordt via een forward search gezocht naar het best passende model:
- Begin met een leeg logistisch regressiemodel (alleen een constante term).
- Bouw stap voor stap een groter model op door steeds één kenmerk toe te voegen dat leidt tot de grootste verbetering in het Bayesiaanse Informatie Criterium (BIC) (zie voor meer informatie over de BIC, de bijlage 4.1.2).
- Stop zodra de BIC-waarde niet meer verbetert door nog een kenmerk toe te voegen.
Deze procedure leidt tot een bepaalde volgorde voor de achtergrondkenmerken, waarbij de kenmerken die het belangrijkste zijn om de kans op vsv te schatten als eerste worden toegevoegd.
Naast de BIC berekenen we voor elk model uit de forward search ook de pseudo-R2-waarde (\( R^{2}_{MZ} \)) als evaluatiemaat (zie bijlage 4.1.2). De \( R^{2}_{MZ} \) geeft een indicatie welke fractie van de totale variantie in vsv wordt verklaard door de achtergrondkenmerken in het model.
Verder voeren we ter vergelijking ook een backward search uit:
- Begin met een volledig logistisch regressiemodel (alle beschikbare kenmerken opgenomen).
- Pel het model stap voor stap verder af door steeds één kenmerk weg te laten dat leidt tot de grootste verbetering qua BIC.
- Stop zodra de BIC niet meer verbetert door nog een kenmerk weg te laten.
Tot slot is er ook nog een combinatie van de forward en backward search gedaan, waarbij toegevoegde kenmerken later weer kunnen worden weggelaten en vice versa. Ter vergelijking worden dezelfde stepwise analyses ook uitgevoerd op het validatiecohort, om te zien in hoeverre de gevonden volgorde van kenmerken voor beide cohorten overeenkomt.
Stap 3: Kruisvalidaties
Op basis van de volgorde van achtergrondkenmerken die gevonden is in stap 2 voeren we een kruisvalidatie uit. De jongeren in de populatie worden verdeeld in vijf willekeurige, even grote groepen. Voor elke groep doen we het volgende:
- Gebruikmakend van de data van alle jongeren die niet behoren tot de huidige deelverzameling, schat alle logistische regressiemodellen waarin de eerste \( q \) achtergrondkenmerken uit de volgorde zijn opgenomen, waarbij \( q \) loopt van 0 tot en met het totale aantal achtergrondkenmerken dat in stap 2 in volgorde is gezet. (Hierbij komt \( q = 0 \) overeen met het ‘lege’ model dat alleen een constante term bevat.)
- Pas elk van de geschatte modellen toe om de kans op vsv te schatten voor de jongeren in de huidige deelverzameling.
Per model geeft deze stap voor alle jongeren in de populatie een geschatte kans op vsv. Dankzij de kruisvalidatie zijn de geschatte kansen voor elke jongere afkomstig uit modellen die zijn geschat zonder die jongere mee te nemen. Op deze manier wordt het risico op overfitting verminderd. Met deze geschatte kansen berekenen we vervolgens de evaluatiematen uit de bijlage 4.1.2: de relatieve entropie \( \Delta(M) \) en \( R^{2}_{MZ} \) gemiddeld over de vijf ronden van de kruisvalidatie. Ook berekenen we de recall, precision en F1-score; zie bijlage 4.1.3. De recall geeft aan hoeveel procent van de daadwerkelijke vsv’ers ook als zodanig worden geschat. Daarnaast geeft de precision aan hoeveel procent van de geschatte vsv’ers dit ook werkelijk zijn. De F1-score vat beide maten samen. Op basis van de uitkomsten uit stap 2 en 3 wordt een voorkeursmodel bepaald.
Stap 4: Multilevel analyse
Een aanname van het logistische regressiemodel is dat een specifieke jongere wel of niet vsv’er wordt, onafhankelijk van alle andere jongeren in de populatie. Aangezien jongeren geclusterd zijn binnen scholen en binnen RMC-regio’s, zou het mogelijk kunnen zijn dat niet aan deze aanname wordt voldaan. Het zou bijvoorbeeld kunnen dat twee jongeren die op dezelfde school zitten relatief vaker of juist relatief minder vaak - afhankelijk van de school - allebei vsv’er worden dan twee jongeren die niet op dezelfde school zitten. Als dit het geval is, kan een betere beschrijving van de data worden verkregen door het logistische regressiemodel uit te breiden met een zogenaamde multilevel-component. Zie bijlage 4.2 voor meer informatie over multilevel analyse.
Om te onderzoeken of het logistische model een dergelijke aanpassing nodig heeft, wordt er eerst onderzocht of er in het voorkeursmodel inderdaad sprake is van clustering. Voor leerlingen in het vo zijn multilevel-modellen getest met een clustering op schoolniveau, op regionaal niveau en met een combinatie van beide typen clustering naast elkaar. Voor studenten in het mbo is geen clustering op schoolniveau onderzocht. Mbo-scholen bestaan vaak uit meerdere, inhoudelijk verschillende, en vaak ook regionaal verspreide vestigingen (soms zelfs over meerdere RMC-regio’s). Gegevens over inschrijvingen op vestigingsniveau zijn voor het mbo momenteel nog niet beschikbaar. Clustering op schoolniveau is voor het mbo dus niet zinvol terwijl clustering op vestigingsniveau op dit moment nog niet onderzocht kan worden. Voor het mbo is daarom alleen clustering op het niveau van RMC-regio onderzocht.
Om te evalueren in hoeverre clustering voorkomt in de data – en daarmee in hoeverre een multilevel-model hier toegevoegde waarde heeft boven een gewoon logistisch regressiemodel – kijken we in dit onderzoek naar het mediane effect van de clustering op de kansverhoudingen (ook wel median odds ratio (MOR) genoemd). De interpretatie van de MOR is vergelijkbaar met die van de eerdergenoemde odds ratio’s, zie bijlage 4.2.2 voor details.
Ten slotte is het belangrijk om op te merken dat, indien er inderdaad sprake is van clustering, dit niet betekent dat de geschatte odds ratio’s uit een logistisch regressiemodel zonder multilevel-component vertekend zijn. Wel kan een multilevel analyse in dat geval mogelijk helpen om nauwkeurigere schattingen van deze odds ratio’s te vinden.
Extra analyses
Tot slot zijn er ook nog extra analyses uitgevoerd. Ten eerste is het voorkeursmodel gevalideerd op het DUO-cohort, door de stepwise analyse (stap 2) ook op die populatie toe te passen. Daarbij wordt zowel de volgorde als de selectie van kenmerken opnieuw bepaald. Op deze manier kunnen de modellen gebaseerd op de CBS- en de DUO-data vergeleken worden.
Daarnaast gebruiken we, vooruitlopend op fase 2 van het onderzoek, het voorkeursmodel voor vo en mbo om een eerste beeld te schetsen van het aantal geschatte vsv’ers per RMC-regio. Daarbij kan op RMC-regio niveau een eerste indruk verkregen worden van de modelkwaliteit, door het werkelijk aandeel vsv’ers te vergelijken met het door het model geschatte aandeel vsv’ers. Hierbij wordt gebruikt gemaakt van een simpele aggregatie (optelling) van de geschatte kansen. In fase 2 zullen bepaalde keuzes rondom de aggregatie gemaakt worden door het ministerie van OCW. Dit zal leiden tot een definitief beeld van het aantal geschatte vsv’ers per RMC-regio.
2) Leerjaar is niet bekend voor mbo-studenten. Hierdoor kan vertraging niet voor de mbo-populatie bepaald worden.
3) Cramérs V wordt berekend via de volgende formule: \( V = \sqrt{\frac{X^2}{n(r-1)}} \), waarbij \( X^2 \) de chi-kwadraat-toetsingsgrootheid is voor de hypothese dat er geen samenhang bestaat tussen het achtergrondkenmerk en vsv, \( n \) het aantal waarnemingen en \( r \) het aantal categorieën van het achtergrondkenmerk (Agresti, 2013, p. 110).