Herijking onderwijsachterstandenindicator primair onderwijs 2021
Vervolgonderzoek naar het actualiseren van het model van de onderwijsachterstandenindicatorOver deze publicatie
Om onderwijsachterstanden in het primair onderwijs (po) te verminderen kent het ministerie van Onderwijs, Cultuur en Wetenschap (OCW) extra middelen toe aan scholen en gemeenten. Het ministerie verdeelt deze middelen aan de hand van de door het Centraal Bureau voor de Statistiek (CBS) ontwikkelde onderwijsachterstandenindicator. Op verzoek van het ministerie heeft het CBS onderzoek gedaan naar het actualiseren van het model dat voor deze indicator wordt gebruikt.
1. Inleiding
Nederland voert sinds de jaren zeventig beleid om de onderwijskansen voor kinderen uit achterstandsmilieus te vergroten. Het beleid is erop gericht onderwijsachterstanden onder (basisschool)leerlingen ten gevolge van sociale, economische of culturele oorzaken zoveel mogelijk te voorkomen en om eenmaal opgelopen achterstanden te verminderen.
In 2018 heeft het ministerie van Onderwijs, Cultuur en Wetenschap (OCW) het onderwijsachterstandenbeleid voor het primair onderwijs (po) en het gemeentelijke onderwijsachterstandenbeleid herzien1). In het sindsdien van kracht zijnde beleid maakt OCW gebruik van de onderwijsachterstandenindicator die het Centraal Bureau voor de Statistiek (CBS) eerder in opdracht van het ministerie heeft ontwikkeld2).
Met deze indicator berekent het CBS voor alle peuters van 2,5 tot 4 jaar en alle basisschoolleerlingen een onderwijsscore. Deze onderwijsscores worden vervolgens conform de Besluiten1 opgeteld tot achterstandsscores per school en per gemeente. Deze drukken dan de verwachte onderwijsachterstandsproblematiek op scholen en in gemeenten uit, op basis waarvan OCW het onderwijsachterstandenbudget over de scholen en gemeenten verdeelt. In 2019 was dit beleid voor het eerst van kracht.
Om de onderwijsachterstandenindicator actueel te kunnen houden, heeft OCW te kennen gegeven de indicator regelmatig te willen evalueren. Hierdoor kunnen nieuwe ontwikkelingen – zoals veranderingen in de samenstelling van de populatie – mee worden genomen in de indicator. De eerste evaluatie is voorzien voor 2021. Bij deze evaluatie hebben we vooral gekeken naar de coëfficiënten en schaalwaarden van het model. Voor deze herziening is niet onderzocht of er ook nieuwe achtergrondvariabelen aan het model kunnen worden toegevoegd. De resultaten van deze eerste herziening worden in dit rapport beschreven. In de periode 2023 tot 2025 volgt een uitgebreide evaluatie waarbij ook de gebruikte achtergrondkenmerken tegen het licht zullen worden gehouden.
Eerder onderzoek
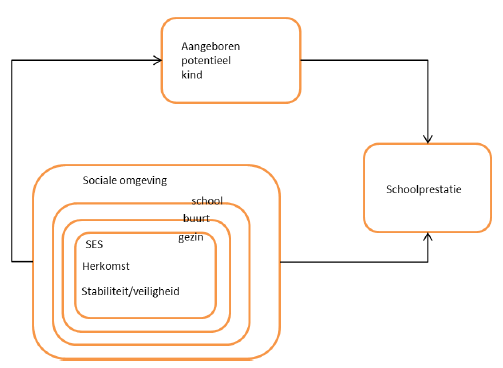
Het conceptuele model in figuur 1.1.1 geeft weer dat onderwijsprestaties niet alleen bepaald worden door het aangeboren potentieel van het kind, maar dat ook diverse achtergrondvariabelen van invloed zijn. In aansluiting op Kloprugge en de Wit (2015) wordt in het kader van de onderwijsachterstandenindicator voor het po gesproken van een onderwijsachterstand als leerlingen door een ongunstige economische, sociale of culturele omgeving op school slechter presteren dan zij bij een gunstiger situatie zouden kunnen.
1.1.1 Conceptueel model
In de eerdere onderzoeken heeft het CBS2) aan de hand van een steekproef van leerlingen van wie een intelligentiemaatstaf bekend was een model geschat waarmee de invloed van verschillende achtergrondkenmerken kan worden bepaald. Uit deze onderzoeken bleek dat achterstanden bij leerlingen in het po het best verklaard konden worden door een combinatie van een zestal achtergrondvariabelen: het opleidingsniveau van de vader, opleidingsniveau van de moeder, verblijfsduur van de moeder in Nederland, land van herkomst van de ouders, of ouders in de Wet Schuldsanering Natuurlijke Personen (WSNP) zitten en het gemiddelde opleidingsniveau van de moeders op school. De bijdragen van deze kenmerken aan de indicator zijn bepaald op basis van een model voor schoolprestaties zoals gemeten door de Centrale Eindtoets van Cito in groep 8.
De genoemde kenmerken zijn voor veel, maar niet alle leerlingen bekend. Ontbrekende informatie wordt, afhankelijk van de informatie die wel bekend is, op verschillende manieren aangevuld. Vervolgens worden de onderwijsscores met een door OCW bepaalde formule geaggregeerd naar een achterstandsscore per schoolvestiging en gemeente. In de formule tellen alleen de scores van kinderen met de laagste 15% onderwijsscores mee. Ook bevatten de besluiten bepalingen over een aftrek (drempelwaarde). Ten slotte wordt op basis van de berekende achterstandsscores het budget door OCW verdeeld. Voor een gedetailleerdere uitleg over de po-indicator, zie het samenvattende rapport.
Naast de methodologische onderzoeken over de ontwikkeling van de indicator2), heeft het CBS na de ingebruikname van de indicator een tweetal monitoring-onderzoeken gepubliceerd3). In deze onderzoeken is gekeken naar de werking van de indicator over de jaren heen. Hoewel de analyses voor de laatste monitor werden gehinderd door het ontbreken van eindtoetsresultaten, laten de resultaten zien dat de werking van de onderwijsachterstandenindicator redelijk stabiel is over de jaren heen.
Vervolgonderzoek
Om het gewicht van de kenmerken in de onderwijsachterstandenindicator te actualiseren heeft OCW het CBS gevraagd om door middel van een vervolgonderzoek hier invulling aan te geven. Het eerste deel van dit onderzoek betreft daarom een herijking van het model van de po-indicator. Omdat het vermoeden bestaat dat de identificatie van asielzoekers en statushouders kan worden verbeterd, wordt dit aspect in het tweede deel van dit onderzoek nader bekeken.
Het oorspronkelijke model is ontwikkeld met behulp van gegevens die zijn verzameld tijdens het Cohortonderzoek Onderwijsloopbanen5-18 (hierna: COOL5-18) en gegevens uit het Stelsel van Sociaal-statistische Bestanden (SSB) van het CBS. Voor de COOL5-18 onderzoeken is bij een steekproef van leerlingen uit groep 5 van het po een proxy voor intelligentie gemeten met de zogenaamde niet-schoolse cognitieve capaciteitentest (NSCCT).
Bij het ontwikkelen van het oorspronkelijke model kon alleen gebruik worden gemaakt van de eerste twee COOL5-18 onderzoeken (afgenomen in de schooljaren 2007/’08 en 2010/’11) vanwege de beschikbaarheid van de eindtoetsgegevens van de onderzoekspopulatie in groep 8. Inmiddels zijn deze gegevens ook beschikbaar voor de deelnemers aan het derde onderzoek van COOL5-18 (afgenomen in schooljaar 2013/’14). Het model voor de po-indicator kan daardoor met behulp van een grotere steekproef worden geschat door de inclusie van recentere gegevens, hetgeen de actualiteit ten goede komt. Er zit dan immers minder tijd tussen het tijdstip waarop de data zijn verzameld die voor de ontwikkeling van het model zijn gebruikt, en het tijdstip waarop het model wordt toegepast op de actuele populatie van peuters en basisschoolleerlingen. Daarnaast zijn bij de oorspronkelijke ontwikkeling alleen indirecte effecten van het opleidingsniveau van de ouders meegenomen. Mogelijk zorgt het rekening houden met indirecte effecten van andere achtergrondvariabelen voor een verdere verbetering van het model voor de onderwijsachterstandenindicator.
In het vierde methoderapport dat ten grondslag ligt aan de huidige indicator is vastgesteld dat het voor asielzoekers en statushouders lastig is om een onderwijsscore te bepalen4). Voor deze kinderen wordt daarom de gemiddelde onderwijsscore geïmputeerd van de kinderen die tot de laagste 15% behoren. Om deze kinderen in de onderzoeksbestanden te kunnen identificeren, worden de COA- en IND-registraties gebruikt. Hiervan wordt vermoed dat sommige asielzoekers met enige vertraging in de registraties worden opgenomen. Het meenemen van de asielinstroom in de maanden na 1 oktober kan mogelijk tot een verbetering leiden van de identificatie van asielzoekers en statushouders in de onderzoekpopulatie.
Onderzoeksvragen
Samengevat, worden in dit rapport de volgende onderzoeksvragen beantwoord:
- Kan een actueler model worden geschat voor het bepalen van het risico op onderwijsachterstand met behulp van additionele data en meer indirecte effecten?
- Kan de identificatie van asielzoekers en statushouders worden verbeterd?
1) Besluit van 27 augustus 2018 tot wijziging van het Besluit bekostiging WPO in verband met het aanpassen van de groeiregeling en van het onderwijsachterstandenbeleid in het primair onderwijs (Staatsblad 2018, 334), en Besluit van 27 augustus 2018, houdende regels met betrekking tot specifieke uitkeringen ten behoeve van het gemeentelijk onderwijsachterstandenbeleid (Besluit specifieke uitkeringen gemeentelijk onderwijsachterstandenbeleid) (Staatsblad 2018, 315).
2) Over het eerdere onderzoek zijn vijf rapporten verschenen, het eerste methoderapport, tweede methoderapport, derde methoderapport, vierde methoderapport en het samenvattend rapport.
3) Om zicht te houden op de werking van de onderwijsachterstandenindicator publiceert het CBS jaarlijks een monitoronderzoek. Het eerste monitoringonderzoek bestrijkt de periode 2017 - 2019; het tweede monitoringonderzoek heeft betrekking op de periode 2017 - 2020.
4) Zie het vierde methoderapport.
2. Methoden en data
Het doel van de herijking is het bepalen in welke mate de omgevingskenmerken uit de po-indicator samenhangen met de schoolprestatie van leerlingen in het primair onderwijs. Het relatieve belang van de diverse kenmerken wordt opnieuw geschat met behulp van geactualiseerde data.
2.1 Methoden voor herijking
Structurele vergelijkingsmodellen
Om onderwijsprestaties zo goed mogelijk te kunnen verklaren is het belangrijk dat een geschikt analysemodel gekozen wordt. In dit onderzoek ontwikkelen we een model waarbij we – net als bij de ontwikkeling van de huidige indicator – corrigeren voor intelligentie. Hiervoor zullen we gebruik maken van structurele vergelijkingsmodellen (Bollen, 1989). Met structurele vergelijkingsmodellen is het mogelijk om onderscheid te maken tussen enerzijds directe effecten van achtergrondvariabelen op schoolprestatie en anderzijds indirecte effecten die via intelligentie lopen. Dit is van belang omdat we uiteindelijk onderwijsachterstanden, oftewel voor intelligentie gecorrigeerde schoolprestaties, willen verklaren. Het doel is om de directe effecten van de overige achtergrondvariabelen (exclusief intelligentie) zo goed mogelijk te kunnen schatten. Hiervoor is het noodzakelijk om ook de indirecte effecten via intelligentie te modelleren. Om rekening te houden met niet-normaliteit en clustering op schoolniveau hebben we de structurele vergelijkingsmodellen geschat met behulp van pseudo maximum likelihood.
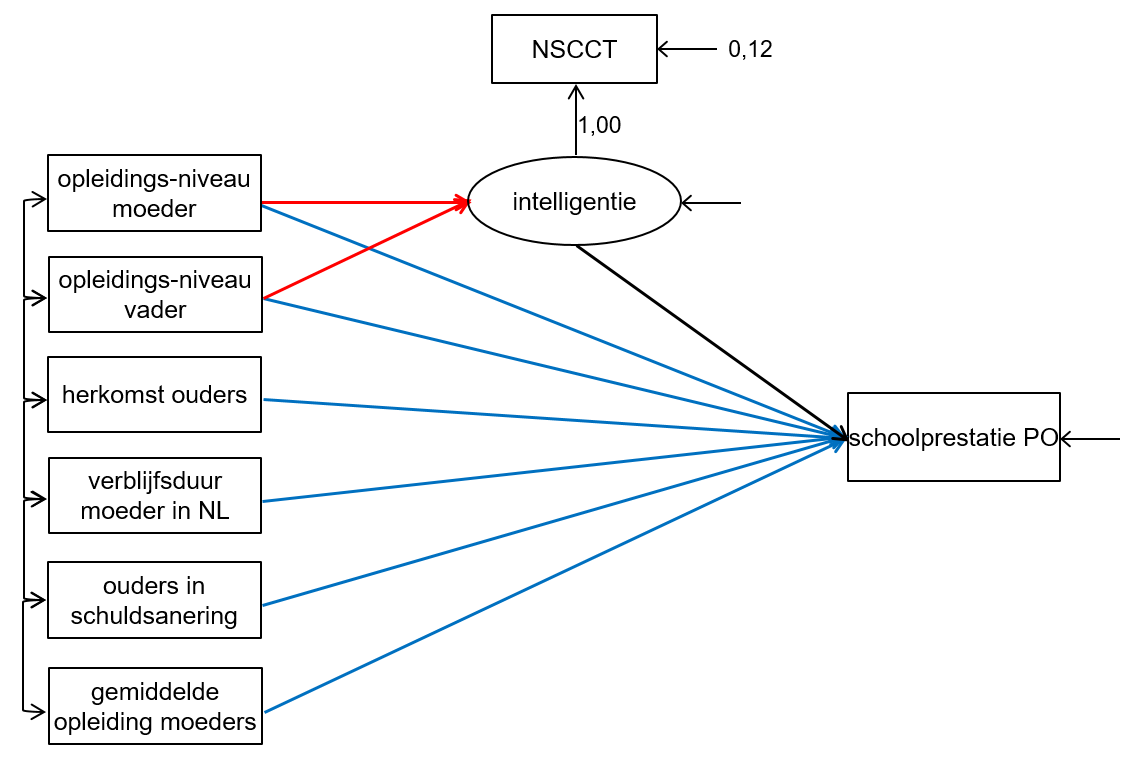
Figuur 2.1.1 geeft schematisch het model van de huidige po-indicator weer. De directe effecten van de omgevingskenmerken worden weergegeven door de blauwe pijlen in de figuur en de indirecte effecten van het opleidingsniveau van beide ouders worden weergegeven door de rode pijlen. In dit onderzoek bekijken we ook of het zinvol is om ook voor de andere omgevingskenmerken indirecte effecten op te nemen in het model. Bij het bepalen of een toevoeging van een indirect effect zinvol is, hebben we gekeken naar twee aspecten. Ten eerste is gekeken of er een theoretische grondslag is voor het toevoegen van zo’n effect. Ten tweede hebben we ook gekeken of de uitkomsten van de modellen aanleiding gaven tot het toevoegen van één of meerdere extra indirecte effecten.
In de indicator voor onderwijsachterstanden in het po worden uiteindelijk alleen de blauwe pijlen meegenomen: dit zijn namelijk de effecten van omgevingskenmerken die verklaren dat leerlingen met dezelfde aanleg (intelligentie) maar een andere omgeving gemiddeld verschillend presteren. Nadelige directe effecten van omgevingskenmerken leiden zo tot onderwijsachterstanden. Een uitgebreide toelichting op het gebruikte model is te vinden in het eerste methodologische rapport van de po-indicator.
2.1.1 Schematische weergave structureel vergelijkingsmodel
Modelselectie
Om de verschillende structurele vergelijkingsmodellen met elkaar te kunnen vergelijken, gebruiken we het Akaike Informatie Criterium (AIC) en het Bayesiaanse Informatie Criterium (BIC) als primaire fitmaten. Een lagere AIC- of BIC-waarde wijst daarbij op een betere modelfit. Enerzijds zorgt het toevoegen van meer verklarende variabelen ervoor dat de waarde van het AIC of BIC daalt. Anderzijds neemt bij het toevoegen van variabelen de kans op overfitten toe. De AIC en BIC houden rekening met deze kans op overfitten via een positieve term die toeneemt met het aantal parameters in het model, zodat complexere modellen in het nadeel zijn. Deze ‘penalty-term’ is (gezien de steekproefomvang van de data die we hier gebruiken) groter bij het BIC dan bij het AIC. Naast de AIC en BIC kijken we ook naar de verklaarde variantie in schoolprestaties. De aangepaste R-kwadraat meet de fractie verklaarde variantie, rekening houdend met de complexiteit van het model.
Verder hebben we, om de volgorde te bepalen waarin mogelijke extra indirecte effecten worden toegevoegd aan het model uit figuur 2.1.1, gebruik gemaakt van zogenaamde modificatie-indices. Bij een gegeven structureel vergelijkingsmodel kan voor elk potentieel effect dat niet is opgenomen in het model een modificatie-index worden berekend die een schatting geeft van de verbetering in de modelfit (zoals gemeten door het AIC of BIC zonder penaltyterm) die op zou treden als dit effect wordt toegevoegd aan het model. Eventuele extra indirecte effecten voegen we aan het model toe op volgorde van de hoogte van de modificatie-index waarbij we het indirecte effect met de hoogste modificatie-index als eerste toevoegen.
Stapsgewijze aanpak
Voor het ontwikkelen van een geactualiseerd model voor de onderwijsachterstandenindicator hebben we een stapsgewijze aanpak gebruikt. Hierbij zal eerst een model worden geschat op basis van de grotere steekproef waaraan de leerlingen uit het derde COOL5-18-onderzoek zijn toegevoegd, met dezelfde directe en indirecte effecten als bij de huidige indicator (het basismodel uit figuur 2.1.1). Vervolgens zal een aantal modellen worden geschat waarin stapsgewijs meer indirecte effecten worden opgenomen onder de voorwaarde dat een dergelijke toevoeging ook zinvol is.
Ten opzichte van de huidige po-indicator hebben we een tweetal verbeteringen doorgevoerd in het basismodel. De eerste verbetering betreft het schatten van het gemiddelde opleidingsniveau van de moeders op een school. Bij het toewijzen van een waarde per school voor het gemiddelde opleidingsniveaus van alle moeders gebruiken we nu de eerder bepaalde schaalwaarden van de opleidingsniveaus van de moeders. Bij de ontwikkeling van de huidige po-indicator werden de schaalwaarden van opleidingsniveau moeder hiervoor opnieuw bepaald via een apart regressiemodel op een grotere dataset. Dit laatste was bij nader inzien niet logisch, omdat later bij het toepassen van de indicator de bijdrage van gemiddeld opleidingsniveau per school wordt berekend op basis van de schaalwaarden die zijn bepaald voor de opleidingsniveaus van de moeders. Het is dan ook logischer om bij het schatten van het model niet uit te gaan van een aparte schatting van de schaalwaarden voor het opleidingsniveau van de moeders ten behoeve van het bepalen van het gemiddelde opleidingsniveau van de moeders op een school. Dezelfde aanpak is ook gevolgd bij het schatten van de andere modellen.
De tweede verbetering betreft het aantal keer dat een specifiek model is geschat. Bij de ontwikkeling van de huidige po-indicator is gebruik gemaakt van één opleidingsniveau variabele per ouder. Deze variabelen bevatten zowel bekende als geïmputeerde opleidingsniveaus. Uit eerder onderzoek (Scholtus en Pannekoek, 2015) weten we dat er een bepaalde onzekerheid zit in de imputaties van het opleidingsniveau. Voor de achtergrondkenmerken hebben we daarom voor beide ouders het opleidingsniveau vijf keer geïmputeerd. Als het opleidingsniveau van een ouder bekend is, zijn deze vijf waarden allemaal gelijk aan de bekende waarde; bij ouders met een onbekend opleidingsniveau variëren de geïmputeerde waarden. Vervolgens hebben we ook ieder model vijf keer geschat en de uitkomsten – fitmaten, modelcoëfficiënten en schaalwaarden– gemiddeld. De standaardfouten en p-waarden van de geschatte coëfficiënten zijn bepaald met behulp van de formules van Rubin (1987) voor multipele imputatie. Op deze wijze wordt de inherente onzekerheid bij het imputeren van het opleidingsniveau in ieder geval gedeeltelijk gecompenseerd.
Analyse effecten op school- en gemeenteniveau
Omdat de onderwijsachterstandsgelden op school- en gemeenteniveau worden verdeeld, hebben we het best passende model ook toegepast op de data van het meest recente productiejaar van de po-indicator. Dit bestand bevat de basisschoolleerlingen van het schooljaar 2020/’21 op basis van peildatum 1 oktober 2020 en de peuters die op 1 oktober 2020 tussen de 2,5 en 4 jaar oud waren. Daardoor kunnen we achterstandsscores voor scholen en gemeenten op basis van de huidige indicator en de herijkte indicator met elkaar vergelijken.
Voor een klein deel van de kinderen is het niet mogelijk om een onderwijsscore uit te rekenen vanwege het ontbreken van één of beide ouders in de Basis Registratie Persoonsgegevens (BRP) of omdat het kind zelf niet in de BRP voorkomt. Bij deze kinderen wordt een onderwijsscore geïmputeerd. Een uitgebreide beschrijving van deze imputatiemethode is te vinden in het vierde methodologische rapport5). Omdat we ook bij de plausibiliteitsanalyses van de achterstandsscores voor scholen en gemeenten in het verleden al hebben gezien dat voor hetzelfde kind de geïmputeerde onderwijsscore van jaar op jaar flink kan veranderen6), lijkt het voor de hand liggend om dit deel van de populatie niet mee te nemen bij de analyses op school- en gemeenteniveau. Echter, deze imputaties zijn niet gelijkmatig over de gehele populatie verdeeld. Sommige scholen of gemeenten kennen een relatief hoog aandeel kinderen waarvan de onderwijsscore is geïmputeerd. Vanwege deze scheve verdeling hebben we voor ieder model ook de onderwijsscores geïmputeerd voor deze kinderen. Daardoor zijn we in staat om op basis van de populatie in het afgelopen schooljaar een volledige simulatie van het effect op school- en gemeenteniveau uit te voeren.
2.2 Gebruikte data voor herijking
Om de vergelijkbaarheid met de huidige indicator te waarborgen gebruiken we voor dit onderzoek dezelfde verrijkte COOL5-18 bestanden als die bij de ontwikkeling van de indicator zijn gebruikt. Deze bestanden bevatten de achtergrondgegevens van alle deelnemende leerlingen die in de schooljaren 2007/2008, 2010/2011 en 2013/2014 in groep 2, 5 of 8 zaten. Uit deze bestanden zullen alleen die leerlingen worden geselecteerd waarvoor in groep 5 een NSCCT-score is opgenomen. Aan deze gegevens zijn uit het SSB de gegevens van de Central Eindtoets van Cito gekoppeld van de betreffende leerlingen in groep 8. Uiteindelijk resulteerde dit in een dataset met gegevens (NSCCT-score, Cito-eindtoetsscore en achtergrondvariabelen) van 19 247 leerlingen. Ter vergelijking: voor het bepalen van de oorspronkelijke po-indicator was een steekproef van 13 466 leerlingen beschikbaar. Het aantal leerlingen steeg doordat nu van meer leerlingen een Cito-eindtoetsscore bekend is dan tijdens eerste onderzoek voor de po-indicator.
Imputaties opleidingsniveau ouders
In het model van de huidige po-indicator zijn de opleidingsniveaus van beide ouders belangrijke voorspellende variabelen voor onderwijsprestaties. Voor kinderen die tot de steekproef behoorden bij de ontwikkeling van het oorspronkelijke model hebben we voor de onbekende opleidingsniveaus, de destijds geïmputeerde opleidingsniveaus overgenomen. Voor de kinderen die zijn toegevoegd aan de onderzoekspopulatie, hebben we in het geval van onbekende opleidingsniveaus deze geïmputeerd met hetzelfde model als bij de ontwikkeling van de oorspronkelijke indicator is gebruikt.
Representativiteit
Om tot een model te komen dat toepasbaar is op de hele populatie van basisschoolleerlingen en peuters is het van belang dat de data een goede afspiegeling vormen van de doelgroep waarvoor het model wordt gebruikt. Uit de technische rapportages van de COOL5-18-onderzoeken wordt duidelijk dat de steekproef representatief is voor de populatie op de basisschool.
Omdat we in dit onderzoek slechts een selectie van de populatie van de COOL5-18-onderzoeken gebruiken – alleen de kinderen die zowel een NSCCT-score in groep 5 als een Cito-eindtoetsscore in groep 8 hebben – hebben we zelf ook nog gekeken naar de representativiteit van de gebruikte selectie.
Om de representativiteit van de uiteindelijk gebruikte steekproef te beoordelen, hebben we gekeken naar in hoeverre de gebruikte selecties uit de drie COOL5-18-onderzoeken onderling overeenkomen. Daarnaast hebben we ook gekeken of er grote afwijkingen zijn met de hele populatie basisschoolleerlingen. Voor deze vergelijking hebben we gekeken naar de opleidingsniveaus van beide ouders en de herkomstcategorie van het kind.
De figuren 2.2.1 en 2.2.2 laten de verdeling van de opleidingsniveaus van de ouders zien (inclusief imputaties). Het is duidelijk te zien dat met name het tweede en het derde COOL5-18-onderzoek vergelijkbaar zijn qua steekproef. In het eerste COOL5-18-onderzoek zijn de hogere opleidingsniveaus iets minder goed vertegenwoordigd, maar echt grote verschillen zijn er niet. Ten opzichte van de verdeling in de data van het meest recente productiejaar van de po-indicator, nemen de lagere opleidingsniveaus een iets groter deel in de steekproef in.
| grp | Basisonderwijs | vmbo-b/k, mbo1 | Vmbo-g/t, avo onderbouw | Mbo2 en mbo3 | Mbo4 | Havo, vwo | Hbo-, wo-bachelor | Hbo-, wo-master, doctor |
|---|---|---|---|---|---|---|---|---|
| 2007 | 11,8 | 16,4 | 5 | 14,9 | 21,3 | 7,7 | 14,6 | 8,3 |
| 2010 | 9,3 | 14,6 | 3,6 | 15,3 | 24,1 | 7,5 | 15,9 | 9,7 |
| 2013 | 8,8 | 14,6 | 4 | 14,1 | 23,3 | 8,3 | 17,5 | 9,5 |
| grp | Basisonderwijs | vmbo-b/k, mbo1 | Vmbo-g/t, avo onderbouw | Mbo2 en mbo3 | Mbo4 | Havo, vwo | Hbo-, wo-bachelor | Hbo-, wo-master, doctor |
|---|---|---|---|---|---|---|---|---|
| 2007 | 14,5 | 13 | 5,9 | 13,6 | 23,7 | 9,6 | 13,8 | 6 |
| 2010 | 10,7 | 11,5 | 5,6 | 13,8 | 26,7 | 8,7 | 14,7 | 8,4 |
| 2013 | 9,6 | 10,3 | 5,5 | 13,5 | 26,9 | 9,1 | 16,6 | 8,6 |
Een andere indicator voor de kwaliteit van de data is de mate waarin het opleidingsniveau van de ouders bekend is. In figuur 2.2.3 is de verdeling hiervan voor de drie COOL5-18-onderzoeken weergegeven. Het is duidelijk te zien dat het aandeel kinderen voor wie van beide ouders het opleidingsniveau bekend is, aanzienlijk toeneemt tussen 2007 en 2013. Het aandeel voor wie van beide ouders het opleidingsniveau onbekend is, neemt daarentegen aanzienlijk af. Omdat ook bij de registraties in het SSB het aantal personen van wie het hoogste opleidingsniveau bekend is toeneemt in de loop van de tijd, is dit in lijn met wat verwacht mag worden.
| grp | Opleidingsniveau beide ouders bekend | Opleidingsniveau moeder onbekend | Opleidingsniveau vader onbekend | Opleidingsniveau beide ouders onbekend |
|---|---|---|---|---|
| 2007 | 18,1 | 15,4 | 18,8 | 47,8 |
| 2010 | 23,9 | 16,4 | 20,5 | 39,3 |
| 2013 | 30,9 | 15,4 | 20,6 | 33,1 |
Als laatste is de verdeling naar herkomst weergegeven in figuur 2.2.4. Zoals is te zien is deze redelijk vergelijkbaar tussen de drie verschillende steekproeven uit de COOL5-18-onderzoeken. Ten opzichte van het meest recente productiejaar van de po-indicator zijn kinderen met een Turkse of Noord-Afrikaanse herkomst enigszins oververtegenwoordigd in de steekproef.
| grp | Nederland | EU-15, andere ontwikkelde economieën | Nieuwe EU-landen en economieën in transitie | Noord-Afrika | Oost-Azië | Overig Afrika, overig Azië, overig Latijns Amerika | Suriname en (voormalige) Nederlandse Antillen | Turkije |
|---|---|---|---|---|---|---|---|---|
| 2007 | 75,9 | 0,9 | 1,3 | 7,8 | 1,2 | 2,8 | 2,7 | 7,3 |
| 2010 | 78,2 | 0,9 | 1,2 | 7,6 | 1,2 | 2,4 | 2,3 | 6,2 |
| 2013 | 76,6 | 1 | 0,9 | 9,3 | 1 | 3,2 | 2,6 | 5,3 |
Concluderend kunnen we zeggen dat de afwijkingen die we zien, geen probleem vormen met betrekking tot de representativiteit van de gebruikte steekproef. Het toevoegen van het derde COOL-onderzoek aan de steekproef lijkt bovendien op alle punten een verbetering: het aandeel ouders met een onbekend opleidingsniveau in de steekproef neemt hierdoor af en de verdeling van opleidingsniveau en herkomst sluit beter aan bij die uit het meest recente productiejaar.
2.3 Toevoegen vertraagd geregistreerde asielzoekers
In de huidige indicator wordt alleen rekening gehouden met asielzoekers en statushouders die tot peildatum 1 oktober van het betreffende schooljaar in de COA- en IND-registraties voorkomen. Omdat er waarschijnlijk vertraging zit in deze registraties, is het wenselijk om te onderzoeken of het meenemen van extra instroomgegevens leidt tot een betere identificatie van asielzoekers en statushouders in het onderzoeksbestand.
Naast het microdatabestand van peildatum 1 oktober 2020 dat eind januari 2021 bij de reguliere productie van de onderwijsachterstandenindicator is gemaakt, zullen de asiel-instroombestanden van de maanden oktober, november en december 2020 worden gebruikt voor deze analyses. In verband met de normale planning van de indicator is het niet zinvol om nog latere instroombestanden te betrekken in de analyses.
Met behulp van deze drie extra asiel-instroombestanden zal per maand bekeken worden hoeveel leerlingen en peuters extra kunnen worden geïdentificeerd als asielzoeker of statushouder. Kanttekening hierbij is wel dat de asiel-instroom als gevolg van de Covid19 crisis aanzienlijk lager is dan normaal. De uitkomsten van deze analyse zullen in dat perspectief moeten worden bezien.
6) Zie de meest recente plausibiliteitsanalyses voor de scholen in het primair onderwijs.
3. Resultaten herijking model
In dit hoofdstuk presenteren we de resultaten van de verschillende modellen. Zoals beschreven in het vorige hoofdstuk hebben we een stapsgewijze aanpak gehanteerd om te komen tot een geactualiseerd model voor de po-indicator. We beginnen met een basismodel dat is geschat met behulp van de grotere steekproef (bassischoolleerleerlingen uit het eerste, tweede én derde COOL5-18-onderzoek). Het basismodel is weergegeven in figuur 2.1.1.
3.1 Basismodel
In principe is dit hetzelfde model als het model van de huidige po-indicator waarbij we twee verbeteringen hebben doorgevoerd, zoals beschreven in paragraaf 2.1 onder “Stapsgewijze aanpak”. De eerste kolommen van Tabel 3.1.1 bevatten de geschatte coëfficiënten, standaardfouten en p-waardes van de directe effecten op schoolprestaties. Daarnaast hebben we ook de gestandaardiseerde coëfficiënten van dit basismodel en de gestandaardiseerde coëfficiënten van de huidige po-indicator opgenomen.
| Kenmerk | Coefficient | standaardfout | gestandaardiseerde coefficient | Gestandaardiseerde coefficient huidig model | |
|---|---|---|---|---|---|
| Opleidingsniveau vader | 0,82 | 0,03 | < 0,001 | 0,17 | 0,18 |
| Opleidingsniveau moeder | 0,82 | 0,03 | < 0,001 | 0,20 | 0,20 |
| Herkomst | -0,78 | 0,11 | < 0,001 | -0,06 | -0,07 |
| Gemiddeld opleidingsniveau moeders op school | 0,08 | 0,11 | 0,474 | 0,01 | 0,02 |
| Verblijfsduur 0 t/m 5 jaar | 0,54 | 0,48 | 0,257 | 0,01 | 0,00 |
| Verblijfsduur 5 t/m 10 jaar | 1,53 | 0,24 | < 0,001 | 0,04 | 0,04 |
| Schuldsanering | -2,07 | 0,55 | < 0,001 | -0,02 | -0,03 |
Van de variabelen naast intelligentie heeft het opleidingsniveau van de ouders duidelijk de sterkste invloed op Cito-scores in groep 8. Om het gevonden effect van opleidingsniveau in het model uit tabel 3.1.1 te duiden, hebben we in de tabellen 3.1.2 en 3.1.3 de schaalwaarden voor de afzonderlijke opleidingscategorieën van vaders en moeders opgenomen. De positieve directe effecten van de twee opleidingsvariabelen op Cito-score (0,82 voor zowel vaders als moeders) laten zien dat lagere opleidingsniveaus samenhangen met lagere Cito-scores, en hogere opleidingsniveaus met hogere Cito-scores. De vergelijking van de gestandaardiseerde coëfficiënten laat zien dat de invloed van het opleidingsniveau van de vaders in het basismodel licht is afgenomen ten opzichte van de huidige po-indicator.
Naast de invloed van de afzonderlijke opleidingsniveaus – de schaalwaarden – hebben we in de tabellen 3.1.2 en 3.1.3 ter vergelijking ook de schaalwaarden van de huidige po-indicator opgenomen. Hierbij wordt duidelijk dat de verandering in schaalwaarde van de afzonderlijke opleidingsniveaus een groter effect heeft dan de verandering in coëfficiënt van de gehele variabele. Bij zowel vaders als moeders gaat de schaalwaarde van basisonderwijs als hoogste opleidingsniveau verder omlaag. Dit betekent dat – ceteris paribus – de onderwijsscore van kinderen van wie één of beide ouders basisonderwijs als hoogste opleidingsniveau hebben, lager uit zal vallen dan bij de huidige po-indicator. Verder valt op dat bij de vaders de schaalwaarden van de hogere opleidingsniveaus meer en vaker afnemen dan de schaalwaarden van de hogere opleidingsniveaus bij de moeders. Omdat we mbo2 en mbo3 als referentieniveau hebben gebruikt, heeft deze categorie altijd nul als schaalwaarde.
| Schaalwaarde basismodel | Schaalwaarde huidige indicator | |
|---|---|---|
| Basisonderwijs | -2,31 | -2,03 |
| Vmbo-b/k, mbo1 | -1,48 | -1,35 |
| Vmbo-g/t, avo onderbouw | 0,75 | 0,79 |
| Mbo2 en mbo3 | 0,00 | 0,00 |
| Mbo4 | 1,32 | 1,82 |
| Havo, vwo | 3,00 | 3,59 |
| Hbo-, wo-bachelor | 3,51 | 3,49 |
| Hbo-, wo-master, doctor | 4,55 | 4,80 |
| Schaalwaarde basismodel | Schaalwaarde huidige indicator | |
|---|---|---|
| Basisonderwijs | -1,25 | -0,91 |
| Vmbo-b/k, mbo1 | -1,75 | -1,75 |
| Vmbo-g/t, avo onderbouw | 1,15 | 1,43 |
| Mbo2 en mbo3 | 0,00 | 0,00 |
| Mbo4 | 1,78 | 1,74 |
| Havo, vwo | 4,18 | 3,82 |
| Hbo-, wo-bachelor | 4,86 | 4,93 |
| Hbo-, wo-master, doctor | 6,12 | 6,19 |
Tabel 3.1.4 geeft een overzicht van de schaalwaarden voor de herkomstvariabele van het basismodel samen met de vergelijkbare waarden van de huidige po-indicator. Omdat we Nederland als referentieniveau hebben gebruikt, is de schaalwaarde van deze categorie altijd nul.
Ook in deze tabel zijn we verschillende verschuivingen. De meeste schaalwaarden komen dichter bij het referentieniveau te liggen. In het geval van de categorieën Nieuwe EU-landen en economieën in transitie en Overig Afrika, overig Azië, overig Latijns Amerika is deze afname zelfs vrij fors. Oost-Azië is de enige categorie waarvoor de schaalwaarde verder van de referentiecategorie komt te liggen. Doordat de coëfficiënt van de herkomstvariabele negatief is, moeten de schaalwaarden ook omgekeerd worden geïnterpreteerd. Kinderen met Oost-Azië als herkomst krijgen daardoor een hogere onderwijsscore terwijl kinderen uit één van de andere herkomstcategorieën (behalve Nederland) juist een lagere onderwijsscore krijgen op basis van hun herkomst.
| Schaalwaarde basismodel | Schaalwaarde huidige indicator | |
|---|---|---|
| Nederland | 0,00 | 0,00 |
| EU-15, andere ontwikkelde economieën | 1,23 | 1,77 |
| Nieuwe EU-landen en economieën in transitie | 0,02 | 0,85 |
| Noord-Afrika | 0,94 | 1,56 |
| Oost-Azië | -1,04 | -0,73 |
| Overig Afrika, overig Azië, overig Latijns Amerika | 0,57 | 1,44 |
| Suriname en (voormalige) Nederlandse Antillen | 2,61 | 3,09 |
| Turkije | 2,91 | 3,22 |
Deze schaalwaarden worden voorafgaand aan het schatten van het structurele vergelijkingsmodel zelf bepaald uit een lineair regressiemodel voor de Cito-eindtoetsscore waarin alle verklarende variabelen (behalve intelligentie en gemiddeld opleidingsniveau per school) zijn opgenomen. Omdat in zo’n regressiemodel geen onderscheid wordt gemaakt tussen directe en indirecte effecten, is er geen verschil in uitkomsten tussen verschillende structurele vergelijkingsmodellen.
Op basis van de zogenaamde modificatie-indices lijkt het zinvol om modellen te schatten met extra indirecte effecten voor herkomst en het gemiddelde opleidingsniveau van de moeders op school. Zoals we in hoofdstuk 2 hebben aangegeven, kijken we eerst of de theoretische grondslag voor dergelijke modellen wel solide genoeg is. We zijn daarbij tot de conclusie gekomen dat de theoretische onderbouwing voor de gedachte dat land van herkomst en het gemiddelde opleidingsniveau van de moeders van invloed is op de intelligentie te beperkt is om het schatten van dergelijke modellen te rechtvaardigen.
3.2 Vergelijking modellen
In de voorgaande paragraaf hebben we het basismodel gepresenteerd. Op basis van de coëfficiënten lijken deze modellen veel op elkaar. Zoals in hoofdstuk 2 uitgelegd, gebruiken we een drietal fitmaten om de modellen te beoordelen: het AIC, het BIC en de aangepaste R-kwadraat. Deze fitmaten zijn samengevat in tabel 3.3.1. Omdat er geen extra modellen zijn geschat, kunnen we deze ook niet met elkaar vergelijken. Wel kunnen we de aangepaste R-kwadraat vergelijken met de aangepaste R-kwadraat van de huidige po-indicator. Deze is bij het nieuwe model marginaal lager; 0,418 ten opzichte van 0,404. Doordat we de modellen voor de nieuwe indicator en de huidige indicator hebben geschat op (deels) verschillende datasets, kunnen we de AIC, BIC en de loglikelihood niet gebruiken om een vergelijking te maken met de huidige po-indicator.
| AIC | 398 694 |
|---|---|
| BIC | 399 080 |
| Aangepaste R kwadraat | 0,404 |
| Loglikelihood | -199 298 |
Om inzicht te geven hoe dit model zich verhoudt tot de huidige po-indicator, hebben we voor de populatie van het meest recente peilmoment (1 oktober 2020) op basis van dit model ook onderwijsscores uitgerekend. Hierbij hebben we voor de kinderen waarvoor niet direct een onderwijsscore kan worden berekend vanwege het ontbreken van noodzakelijk achtergrondkenmerken, de onderwijsscores geïmputeerd volgens de normale procedure . Vervolgens hebben we de onderwijsscores van de huidige po-indicator vergeleken met deze nieuwe onderwijsscores. In figuur 3.2.2 hebben we deze twee scores tegen elkaar afgezet in een zogenaamde tweedimensionale dichtheidsgrafiek.
3.2.2 Onderwijsscores huidige indicator t.o.v. nieuw model
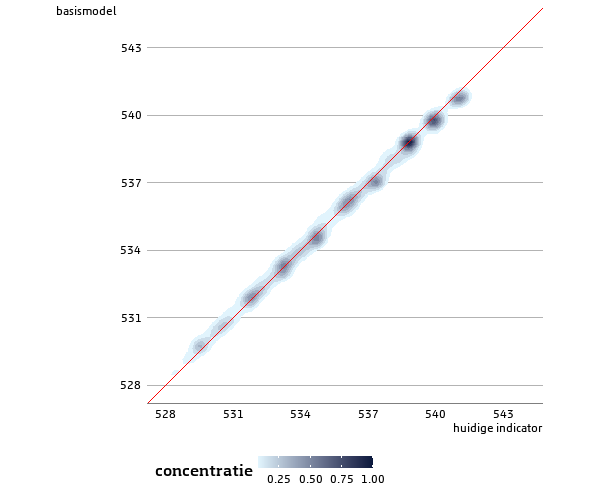
Uit figuur 3.2.2 valt af te leiden dat de onderwijsscores van het nieuwe model altijd in de buurt liggen van de onderwijsscores op basis van de huidige po-indicator. Dit is ook terug te zien in de hoge correlatie tussen deze twee waarden (r = 0,97, p < 0,0001). In tabel 3.2.3 hebben we het verschil tussen deze twee onderwijsscores samengevat. In de gehele populatie ligt de onderwijsscore op basis van het nieuwe model gemiddeld 0,04 punt lager dan in de huidige po-indicator. Voor de kinderen voor wie direct een onderwijsscore kan worden berekend, ligt de verandering in onderwijsscore in 95% van de gevallen tussen de -0,65 en +0,54. Hoewel deze verschillen redelijk klein zijn, kan dit met name voor kinderen met een onderwijsscore rondom de grenswaarde ervoor zorgen dat deze kinderen met het nieuwe model ineens wel of niet tot de doelgroep behoren. Uit de vergelijking van de deelpopulaties – direct bepaalde onderwijsscore of geïmputeerde onderwijsscore – blijkt dat de hoogte van de standaarddeviatie van de gehele populatie fors wordt beïnvloed door de relatief hoge standaarddeviatie van de kinderen voor wie een onderwijsscore wordt geïmputeerd. Op de oorzaak van deze relatief hoge standaarddeviatie gaan we in hoofdstuk 4 dieper in bij het bespreken van de effecten op school- en gemeenteniveau.
| Gemiddeld verschil | Standaard- deviatie | Ondergrens | Bovengrens | |
|---|---|---|---|---|
| Totaal peuters & leerlingen | -0,04 | 0,84 | -1,72 | 1,64 |
| Direct bepaald | -0,06 | 0,3 | -0,65 | 0,54 |
| Geïmputeerd | 0,19 | 3,03 | -5,88 | 6,25 |
4. Effecten voor scholen en gemeenten
In het vorige hoofdstuk hebben we de resultaten besproken van het nieuw geschatte model. Daarbij hebben we gezien dat zowel bij de coëfficiënten als bij de schaalwaarden verschillende verschuivingen ten opzichte van het huidige model plaats vinden. In dit hoofdstuk gaan we dieper in op de effecten van deze veranderingen in het model op school- en gemeenteniveau. Voor deze analyse gaan we uit van het in het vorige hoofdstuk besproken basismodel. Zoals uitgelegd in paragraaf 2.1 hebben we voor kinderen voor wie niet een onderwijsscore kan worden uitgerekend, een onderwijsscore geïmputeerd volgens de procedure zoals die ook in de po-indicator wordt gebruikt. Daar waar we in dit hoofdstuk en de rest van het rapport praten over scholen, bedoelen we schoolvestigingen.
4.1 Effecten scholen
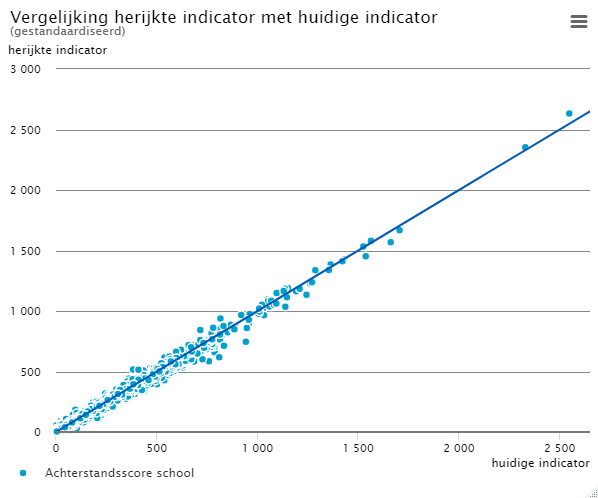
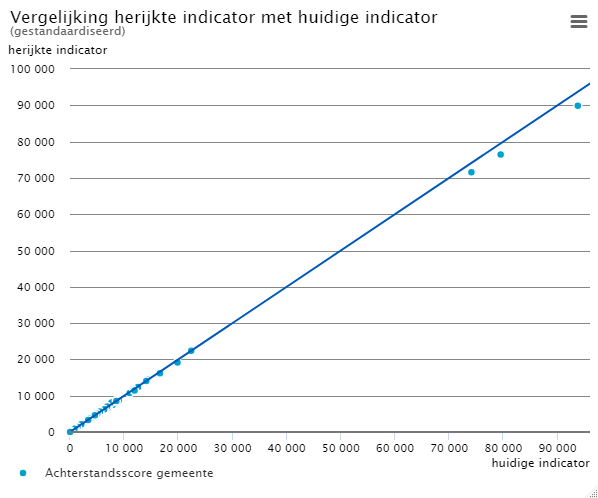
Omdat de som van de achterstandsscores op basis van het nieuwe model afwijkt van de som van de achterstandsscores van de huidige po-indicator, hebben we de achterstandsscores gestandaardiseerd. Deze gestandaardiseerde achterstandsscores wijken af van de officieel gepubliceerde achterstandsscores. In figuur 4.1.1 vergelijken we deze gestandaardiseerde scores van de huidige indicator en het nieuwe model met elkaar. Om de vergelijking tussen oud en nieuw te vergemakkelijken hebben we ook een diagonaallijn in figuur 4.1.1 opgenomen. Alle punten die onder de diagonaal liggen vertegenwoordigen scholen die er met de nieuwe indicator op achteruit zullen gaan.
De gestandaardiseerde achterstandsscore van individuele scholen en gemeenten zijn in een aparte tabel gepubliceerd.
Zoals in figuur 4.1.1 is te zien, liggen de meeste punten in de buurt van de diagonaal. Dit betekent dat de meest scholen kunnen verwachten dat de herijkte achterstandsscore in de buurt ligt van de achterstandsscore die is gebaseerd op de achterstandsscore volgens de huidige po-indicator.
4.1.1 Vergelijking indicatoren scholen op basis van gestandaardiseerde achterstandsscores
In aanvulling op figuur 4.1.1 hebben we in tabel 4.1.2 een kruistabel weergegeven met daarin de aantallen basisscholen die op basis van huidige of de herijkte indicator een achterstandsscore hoger dan nul hebben.
| Herijkte score gelijk aan 0 | Herijkte score groter dan 0 | |
|---|---|---|
| Huidige score gelijk aan 0 | 3 577 | 133 |
| Huidige score groter dan 0 | 41 | 2 497 |
Van alle basisscholen krijgen 41 basisscholen met de herijkte indicator een score van nul terwijl deze scholen met de huidige indicator nog een score hoger dan nul kregen. Andersom zijn er 133 scholen die op basis van de huidige indicator een score gelijk aan nul kregen, die met de herijkte indicator een score van hoger dan nul krijgen. Beide groepen scholen bestaan hoofdzakelijk uit scholen met een lage achterstandsscore.
Om het beeld van de verandering van de herijkte indicator ten opzichte van de huidige indicator verder in te vullen, hebben we in figuur 4.1.3 de verdeling van de verandering in de achterstandsscore voor scholen gevisualiseerd. Voor deze figuur hebben we de groep scholen die met zowel de huidige als de herijkte indicator een score gelijk aan nul krijgt buiten beschouwing gelaten.
4.1.3 Verdeling verandering achterstandsscore scholen
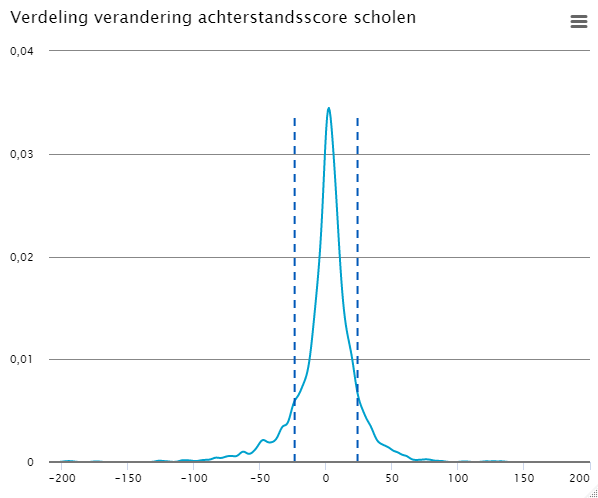
Uit figuur 4.1.3 kunnen we afleiden dat de verandering in achterstandsscore voor veel scholen redelijk klein is. In tabel 4.1.4 hebben we deze verandering ook weergegeven in een frequentietabel waarbij we de verandering in score hebben opgedeeld in groepen. De grenswaarden voor deze groepen hebben we bepaald door de standaarddeviatie één of twee keer bij het gemiddelde op te tellen of af te trekken. Voor bijna 80 procent van de scholen ligt deze verandering in achterstandspunten (afgerond) tussen de -24 en +24.
| Aantal | |
|---|---|
| Minder dan -47.7 | 107 |
| -47.7 tot -23.8 | 195 |
| -23.8 tot 0 | 869 |
| 0 tot 23.8 | 1 239 |
| 23.8 tot 47.7 | 205 |
| Meer dan 47.7 | 56 |
Indien we ook rekening houden met de scholen die zowel in de huidige als in de herijkte indicator geen score van boven nul krijgen, dan neemt de bandbreedte af tot respectievelijk -16 en +16. Het aandeel scholen dat dan binnen deze bandbreedte valt neemt toe tot ca. 85 procent.
De vraag is nu waardoor die veranderingen ontstaan. In hoofdstuk 3 hebben we gezien dat zowel de coëfficiënten als de schaalwaarden soms fors kunnen veranderen. Als we inzoomen op de scholen die er het meest op achteruitgaan, dan kunnen we die groep scholen beschrijven aan de hand van een aantal vergelijkbare kenmerken. Ten eerste zien we dat op deze scholen voor een relatief groot aandeel van de leerlingen de onderwijsscore wordt geïmputeerd, met een aantal uitschieters tot boven de 40 procent. Deze imputaties worden voornamelijk met behulp van predictive mean matching (PMM) uitgevoerd . Doordat de leerlingen in het herijkte model een andere onderwijsscore krijgen verandert ook het PMM-model. Dit heeft tot gevolg dat er ook andere donoren worden geselecteerd waarvan de onderwijsscore wordt geïmputeerd bij leerlingen waarvan geen onderwijsscore is uitgerekend. Als tweede zien we dat de kinderen op deze scholen waarvoor wel een onderwijsscore kan worden uitgerekend, vooral afkomstig zijn uit de herkomstgebieden Nieuwe EU-landen en economieën in transitie, Noord-Afrika, Suriname en Antillen en Overig. Dit was te verwachten omdat we in paragraaf 3.1 hebben gezien dat de schaalwaarden – ook na vermenigvuldiging met de coëfficiënt voor herkomst – voor deze groepen zijn afgenomen. Daardoor hebben deze kinderen een kleinere kans om onder de grenswaarde te komen en tellen ze dus ook niet mee bij de berekening van de achterstandsscore van de school. Ten derde zien we dat sommige van deze scholen ook worden gekenmerkt door een relatief hoog aandeel moeders waarvan de verblijfsduur in Nederland korter is dan 5 jaar. Ook hiervan hebben we in hoofdstuk 3 gezien dan de coëfficiënt voor deze groep is toegenomen waardoor ook de kans om onder de grenswaarde te komen weer kleiner wordt. Als laatste zien we ook dat sommige van deze scholen een relatief hoog aandeel leerlingen hebben waarvan één of beide ouders onder de Wet Schuldsanering Natuurlijke Personen vallen. Ook hier geldt weer dat de coëfficiënt hiervoor is afgenomen waardoor de kans om onder de grenswaarde te komen kleiner is geworden.
Ook scholen die er veel op vooruitgaan qua (gestandaardiseerde) achterstandsscore worden vaak gekenmerkt door een hoog aandeel leerlingen voor wie een onderwijsscore moet worden geïmputeerd. Doordat ook voor deze leerlingen de input van de PMM-methode verandert, worden ook voor hen andere donoren geselecteerd. Deze donorselectie pakt voor deze scholen dus voordelig uit doordat vaker een donor wordt geselecteerd met een onderwijsscore onder de grenswaarde. Sommige van de scholen die er veel op vooruit gaan worden ook gekenmerkt door een hoog aandeel leerlingen met Turkije als herkomstgroep. Dit komt doordat deze leerlingen weliswaar een lagere schaalwaarde hebben voor de herkomstvariabele in het herijkte model, maar deze lagere schaalwaarde wordt grotendeels gecompenseerd door de hogere coëfficiënt. Het netto effect is vervolgens dat de onderwijsscore voor leerlingen met een Turkse herkomst slechts minder dan tweehonderdste toeneemt als gevolg van hun herkomst. Gecombineerd met het gegeven dat de grenswaarde van de herijkte indicator ongeveer 0,13 hoger ligt, zorgt dit ervoor dat kinderen van Turkse herkomst juist een grotere kans hebben om onder de grenswaarde uit te komen en dus bij te dragen aan de achterstandsscore van hun school.
4.2 Effecten gemeenten
Net als voor de scholen in het basisonderwijs hebben we voor de gemeenten achterstandsscores uitgerekend met zowel de huidige indicator als de herijkte indicator. Vervolgens hebben we ook deze scores gestandaardiseerd om ze met elkaar te kunnen vergelijken. In figuur 4.2.1 hebben we deze achterstandsscore tegen elkaar afzet. In vergelijking met de scholen zien we dat de punten relatief dichter tegen de diagonaallijn aanliggen. Dit betekent dat de herverdeeleffecten relatief gezien kleiner zijn dan bij de scholen.
4.2.1 Vergelijking indicatoren gemeenten op basis van gestandaardiseerde achterstandsscores
In deze grafiek wijken de drie gemeenten met de hoogste achterstandsscore – Rotterdam, Amsterdam en Den Haag – het meeste af van de diagonaal. Hoewel de vermindering in achterstandspunten groot lijkt is deze relatief gezien beperkt; voor alle drie deze gemeenten bedraagt deze daling ongeveer 4%. De gemeenten die er relatief gezien het meest op vooruit of achteruit gaan, zijn hoofdzakelijk gemeenten met een kleine achterstandsscore.
Om het beeld van de verandering van de herijkte indicator ten opzichte van de huidige indicator verder in te vullen, hebben we in figuur 4.2.2 de verdeling van de verandering in de achterstandsscore voor gemeenten gevisualiseerd. Uit deze figuur valt duidelijk op te maken dat het aandeel gemeenten dat er op vooruit gaat aanzienlijk groter is dan het aandeel gemeenten dat er op achteruit gaat. Voor deze figuur hebben we de groep gemeenten die met zowel de huidige als de herijkte indicator een score gelijk aan nul krijgt buiten beschouwing gelaten. Verder hebben we ook de gemeenten Rotterdam, Amsterdam en Den Haag niet opgenomen in deze figuur omdat de verandering in absolute zin voor deze gemeenten sterk afwijkt van de verandering bij de andere gemeenten. Door deze drie gemeenten niet op te nemen is de figuur makkelijker te interpreteren.
4.2.2 Verdeling verandering in achterstandsscore gemeenten
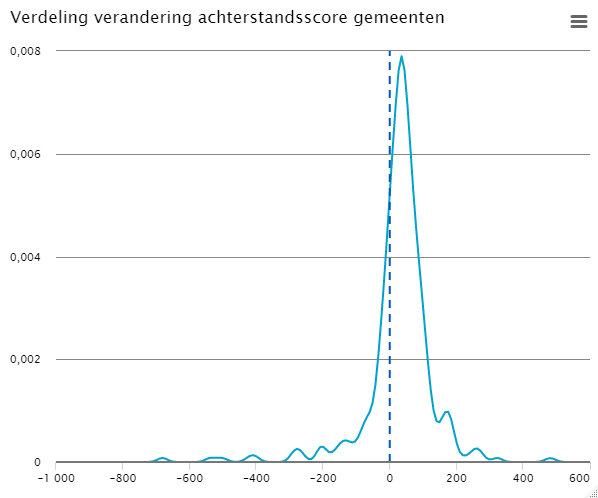
Uit figuur 4.2.2 valt af te leiden dat veruit de grootste groep gemeenten een relatief kleine verandering in de achterstandsscore ziet van tussen de 0 en +100. Dit zien we ook terug als we de verandering van de achterstandsscore relateren aan de achterstandsscore volgens de methode van de huidige indicator. Voor de meeste gemeente valt de relatieve verandering tussen de -6 en +22 procent. De meeste gemeenten die een toename van meer dan tien procent zien, betreffen gemeenten met een (relatief) lage achterstandsscore.
Ook voor de gemeenten hebben we gekeken waardoor die verandering ontstaan. De verklaring is vergelijkbaar met die voor de scholen. De gemeenten die er het meest op achteruitgaan worden gekenmerkt door relatief hoge percentages geïmputeerde onderwijsscores, een oververtegenwoordiging van de herkomstgroepen Nieuwe EU-landen en economieën in transitie, Noord-Afrika, Suriname en Antillen en Overig. Ook worden sommige van deze gemeenten gekenmerkt door een relatief hoog aandeel moeders waarvan de verblijfsduur in Nederland korter is dan 5 jaar.
In tegenstelling tot bij de scholen worden gemeenten die er redelijk veel op vooruitgaan juist niet gekenmerkt door ook een relatief hoog aandeel geïmputeerde onderwijsscores. Toch zien we dat een flink deel van de vooruitgang bij deze gemeenten het gevolg is van kinderen die eerst niet en met de herijkte methode wel een onderwijsscore van onder de grenswaarde krijgen geïmputeerd. Zoals we al eerder hebben uitgelegd bij de scholen is dit het gevolg van de samenstelling van de groep kinderen in een gemeente en de wijze waarop de donorselectie is vormgegeven. Verder zien we ook bij deze gemeenten dat bij de kinderen voor wie wel een onderwijsscore kan worden uitgerekend én die volgens het huidige model niet en volgens het herijkte model wel onder de grenswaarde komen, vaak één of beide ouders een laag opleidingsniveau hebben. In hoofdstuk 3 hebben we gezien dat voor deze groepen de schaalwaarde afneemt waardoor de kans groter wordt dat de onderwijsscore onder de grenswaarde uitkomt.
5. Resultaten meenemen extra asielinstroom
In de huidige indicator wordt alleen rekening gehouden met asielzoekers en statushouders die tot peildatum 1 oktober van het betreffende schooljaar in de COA- en IND-registraties voorkomen. Omdat we vermoeden dat er vertraging zit in deze registraties hebben we gekeken of het meenemen van extra instroomgegevens leidt tot een betere identificatie van asielzoekers en statushouders in de onderzoekspopulatie. Daarvoor hebben we de asielinstroom gegevens van de maanden oktober, november en december 2020 aan het onderzoeksbestand dat is gebaseerd op peildatum 1 oktober 2020 gekoppeld. Kanttekening hierbij is wel dat de asiel-instroom als gevolg van de Covid19 crisis in deze maanden aanzienlijk lager was dan normaal waardoor de in dit hoofdstuk gepresenteerde uitkomsten waarschijnlijk een onderschatting zijn van het effect van het meenemen van extra asielinstroom gegevens.
Door het meenemen van de extra asielinstroom gegevens konden we 44 kinderen als asielzoeker of statushouder identificeren. Van deze 44 gevallen waren 41 kinderen in de schoolgaande leeftijd en 3 kinderen in de leeftijd van 2,5 tot 4 jaar. De basisschoolleerlingen zijn enigszins geclusterd op een aantal scholen. Bij één school werden 5 kinderen extra geïdentificeerd, bij 4 scholen drie kinderen extra. De scholen en gemeenten waar één of meer extra kinderen als asielzoeker of statushouder konden worden geïdentificeerd, krijgen als gevolg daarvan een hogere achterstandsscore.
De omvang van de groep die extra kan worden geïdentificeerd, is beperkt en – zoals eerder gesteld – waarschijnlijk een onderschatting als gevolg van de Covid19 crisis. Op het niveau van de hele populatie is het effect van het meenemen van de extra instroom gering. Echter, het effect is geconcentreerd bij een beperkt aantal scholen en gemeenten. Het lijkt ons daarom zinvol om deze extra instroom mee te nemen in het proces van het bepalen van de achterstandsscores.
6. Samenvatting & conclusies
Om de onderwijsachterstandenindicator actueel te houden wil het ministerie van Onderwijs, Cultuur en Wetenschap regelmatig evalueren en herijken. Het doel hiervan is dat het gebruikte model ontwikkelingen in de populatie in de tijd volgt. In de evaluatie die we in dit rapport hebben besproken, staan vooral de coëfficiënten en schaalwaarden van het model van de po-indicator centraal. Daarnaast hebben we gekeken naar het effect van het meenemen van extra asielinstroom gegevens voor de identificatie van asielzoekers en statushouders.
In hoofdstuk 3 hebben we de resultaten gepresenteerd van het opnieuw schatten van de coëfficiënten en schaalwaarden aan de hand van een grotere steekproef. Hierbij hebben we een recentere periode toegevoegd aan de steekproeven die zijn gebruikt bij de ontwikkeling van de huidige po-indicator. Hoewel technisch mogelijk hebben we geen modellen beschreven waarin rekening wordt gehouden met extra indirecte effecten. Dit bleek theoretisch niet goed onderbouwd te kunnen worden. De resultaten van het toevoegen van een recentere periode laten zien dat de invloed van een aantal variabelen sterker wordt. De lagere opleidingsniveaus, sommige herkomstgroepen en verblijfsduur korter dan 5 jaar krijgen een grotere invloed op de onderwijsscore van het kind. De invloed van sommige andere herkomstgroepen, het gemiddeld opleidingsniveau van de moeders op en een school en ouders in de schuldsanering neemt daarentegen af.
Wat het effect is van deze veranderingen op school- en gemeenteniveau hebben we in hoofdstuk 4 besproken. Om het effect van de herijkte methode ten opzichte van de huidige methode van de po-indicator goed te kunnen analyseren hebben we de achterstandsscores gestandaardiseerd. Daarbij hebben we gezien dat de veranderingen in achterstandsscores te verklaren zijn op basis van de veranderingen in het model. Bij scholen en gemeenten waar de veranderingen het grootst zijn, is een aanzienlijk deel van de verandering het gevolg van de imputatie van de onderwijsscores bij kinderen waarvoor we geen onderwijsscore uit kunnen rekenen. Echter, deze veranderingen zijn ook een gevolg van de veranderingen in het herijkte model. Doordat de input hiervoor verandert, verandert ook de donorselectie. Voor sommige scholen en gemeenten pakt dit positief uit, voor sommige scholen en gemeenten negatief. Dit resultaat was te verwachten omdat we ook bij de plausibiliteitsanalyses van achterstandsscores voor scholen en gemeenten in het verleden al hebben gezien dat voor hetzelfde kind de geïmputeerde onderwijsscore van jaar op jaar flink kan veranderen.
Als laatste hebben we ook gekeken naar het effect van het meenemen van extra asielinstroom gegevens voor de identificatie van asielzoekers en statushouders in het onderzoeksbestand. Hoewel het effect hiervan klein is, zijn er geen belemmeringen om deze extra gegevens niet mee te nemen.
Referenties
Bollen, K.A. (1989). Structural Equations with Latent Variables. John Wiley & Sons: New York.
Kloprogge, J. en de Wit, W. (2015). Het onderwijsachterstandenbeleid na 2015. Literatuurstudie
t.b.v. expertbijeenkomst OAB september 2015. Nationaal Regieorgaan Onderwijsonderzoek.
Rubin, D.B. (1987), Multiple Imputation for Nonresponse in Surveys. John Wiley & Sons, New York.
Scholtus, S. en Pannekoek, J. (2015). Massa-imputatie van opleidingsniveaus. Centraal Bureau voor de Statistiek, Den Haag.
Privacy
Het CBS verzamelt gegevens van natuurlijke personen, bedrijven en instellingen. Dit is wettelijk vastgelegd in de CBS-wet en de Algemene Verordening Gegevensbescherming (AVG). Identificerende persoonskenmerken worden na ontvangst direct gepseudonimiseerd. Hierdoor kan het onderzoek alleen worden uitgevoerd op gegevens met een pseudosleutel. Bij publicatie zorgt het CBS er bovendien voor dat natuurlijke personen of bedrijven niet herkenbaar of herleidbaar zijn. Ook hanteert het CBS diverse maatregelen tegen diefstal, verlies of misbruik van persoonsgegevens. Het CBS levert geen herkenbare gegevens aan derden, ook niet aan andere overheidsinstellingen. Wel kunnen sommige (wetenschappelijke) instellingen onder strenge voorwaarden toegang krijgen tot gegevens met pseudosleutel op persoons- of bedrijfsniveau. Dit noemen we microdata.
Voor meer informatie, zie onze website: www.cbs.nl/privacy.